elasticsearch的rest搜索--- 查询
时间:2015-07-22 18:19:31
收藏:0
阅读:444
目录: 一、 针对这次装B 的解释
四、 查询
四、 查询
1. 查询的官网的文档
2. 查询的rest格式
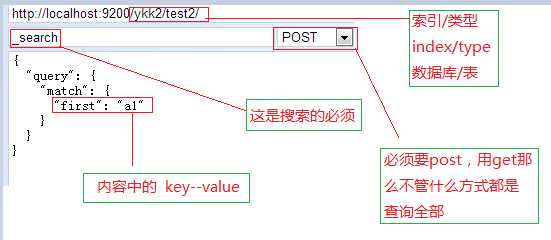
3. 介绍用过的查询方式
一般的查询
http://blog.csdn.net/dm_vincent/article/details/41820537
查询出的数据字段的解释
- took —— Elasticsearch执行这个搜索的耗时,以毫秒为单位- timed_out —— 指明这个搜索是否超时
- _shards —— 指出多少个分片被搜索了,同时也指出了成功/失败的被搜索的shards的数量
- hits —— 搜索结果
- hits.total —— 能够匹配我们查询标准的文档的总数目
- hits.hits —— 真正的搜索结果数据(默认只显示前10个文档)- _score和max_score —— 现在先忽略这些字段
(1) match匹配
"query":{"match":{"UserName":"BWH-PC"}}
match是匹配一个key对应的value,value可以是多个,但是必须是这个字段下的,查找多个字段的是不行
{"query": {"match": {"text": "quick fox"}}}相当于{"query": {"bool": {"should": [{"term": { "text": "quick" }},{"term": { "text": "fox" }}]}}}
(2) multi_match 匹配
{"query": {"multi_match": {"query": "bbc0641345dd8224ce81bbc79218a16f","operator": "or","fields": ["*.machine"]}}}
注意:如果没有machine这个字段,就会报错,需要在fields后面添加一个""
fields中可以添加*做模糊----fields": ["f*.name"]【查询的是f开头的】
"operator":"or" 指的是对query中的多个值查询方式
其中的type的配置报错,需要进一步学习
(3) bool查询
{"bool": {"must": { "match": { "title": "how to make millions" }},"must_not": { "match": { "tag": "spam" }},"should": [{ "match": { "tag": "starred" }},{ "range": { "date": { "gte": "2014-01-01" }}}]}}
must:所有分句都必须匹配,与 AND 相同。
must_not:所有分句都必须不匹配,与 NOT 相同。
should:至少有一个分句匹配,与 OR 相同。
(4) term查询
(a) 在term查询中,字段是field.name1,那么term不能查,以为"."必须是域
"term":{"f1.name":"a1"}-----那么意思是查找的是f1的field下面的name
但是数据中有"f1.name":"a1" ,那么term是查找不到这个, 所以数据中的key不能有"."
(b) 在term中查询时候,查询的字段的值不能有大写,但是可以有空格 ---- 对数据中有大写,那么查询用小写,也会匹配到那个值的
"term": {"CapabilityDescriptions": "aa"}
(5)不计算存在的次数,判断存在就1分,当然可以指定分数
{"query": {"bool": {"should": [{ "constant_score": {"query": { "match": { "description": "wifi" }}}},{ "constant_score": {"query": { "match": { "description": "garden" }}}},{ "constant_score": {"boost": 2"query": { "match": { "description": "pool" }}}}]}}}
(6) exists 过滤器 相当于is not null
missing相当于is null【没查到的是null】
(7) 过滤查询---了解到这种过滤会使得查询效率高,而不是单纯的查询完以后的过滤
当执行 filtered 查询时,filter 会比 query 早执行。结果字节集会被传给 query 来跳过已经被排除的文档。这种过滤器提升性能的方式,查询更少的文档意味着更快的速度。
(a)query带match filter带term 【term是精确匹配单个字段 , terms中可以写多个的term】
{
"query": {"filtered": {"query": { "match": { "email": "business opportunity" }},"filter": { "term": { "folder": "inbox" }}}}}
(b)query没有,默认是查询match_all , fliter中带bool 【bool中再使用match或者match_all,需要用query包】
{"query": {"filtered": {"filter": {"bool": {"must": { "term": { "folder": "inbox" }},"must_not": {"query": {"match": { "email": "urgent business proposal" }}}}}}}}
(c) tie_breaker ,在标题的网址中去查,是最佳字段的调优,是将匹配度乘以这个值
tie_breaker的取值范围是0到1之间的浮点数,取0时即为仅使用最佳匹配子句(译注:和不使用tie_breaker参数的dis_max查询效果相同),取1则会将所有匹配的子句一视同仁。
它的确切值需要根据你的数据和查询进行调整,但是一个合理的值会靠近0,(比如,0.1 -0.4),来确保不会压倒dis_max查询具有的最佳匹配性质。
(d)range 过滤器,让你可以根据范围过滤:range过滤器也可以用于日期字段
"range" : {"price" : {"gt" : 20,"lt" : 40}}--------------------------{"query" : {"filtered" : {"filter" : {"range" : {"price" : {"gte" : 20,"lt" : 40}}}}}}----------------------"range" : {"timestamp" : {"gt" : "2014-01-01 00:00:00","lt" : "2014-01-07 00:00:00"}}到所有最近一个小时的文档:"range" : {"timestamp" : {"gt" : "now-1h"}}
(e) 区别于 filtered ,post_filter查询就是先查询,后过滤, 效率没有前面的高
后置过滤--post_filter元素是一个顶层元素,只会对搜索结果进行过滤。警告:性能考量只有当你需要对搜索结果和聚合使用不同的过滤方式时才考虑使用post_filter。有时一些用户会直接在常规搜索中使用post_filter。不要这样做!post_filter会在查询之后才会被执行,因此会失去过滤在性能上帮助(比如缓存)。post_filter应该只和聚合一起使用,并且仅当你使用了不同的过滤条件时。
----下面的例子是可以过滤field的,multi_match必须使用query包,
match只能过滤没有被“包”的,必须multi_match是过滤被"包"的,
query_string中的是全文搜索,是可以查到所有的数据
eg:查询machine是bbc0641345dd8224ce81bbc79218a16f,不管是否被字段包,都需要过滤出来{"query": {"query_string": {"query": "*"}},"post_filter": {"bool": {"should":{"query": {"bool": {"should": [{"match": {"machine": "bbc0641345dd8224ce81bbc79218a16f"}},{"match": {"machine": "bbc0641345dd8224ce81bbc79218a16f"}}]}}}}}}当然,在里面的每一个should中,可以去做很多变形,但是should多个子类时,必须用[]{"query": {"query_string": {"query": "*"}},"post_filter": {"bool": {"should": [{"query": {"bool": {"must": [{"multi_match": {"query": "bbc0641345dd8224ce81bbc79218a16f","operator": "or","fields": ["*.machine",""]}},{"multi_match": {"query": "10.10.185.99","operator": "or","fields": ["*.IPAddress",""]}}]}}},{"query": {"bool": {"must": [{"match": {"machine": "bbc0641345dd8224ce81bbc79218a16f"}},{"match": {"IPAddress": "10.10.11.11"}}]}}}]}}}
(f) 这是查询中最让人恶心的:查询到结果以后,进行过滤(或者过滤以后进行查询)----其实这种复杂的,直接在query中查,最后在_score中过滤,0.1以下的就是不匹配(同事不让,原因不明,我感觉这很好用)


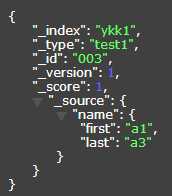
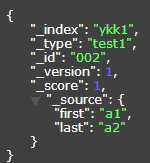
在一般的过滤中,比如"first":"a1" 那么只能过滤到第二个,不被name包的
但是有时候,对于field没创建好的情况下,需要"包","不包"的都匹配上,就需要使用multi_match和match的联用
在过滤中可以用match或者multi_match,query_string放的方式用query包
eg:查询 last = a2的,不管包还是不包的都要查询出来
{"query": {"filtered": {"query": {"query_string": {"query": "*"}},"filter": {"bool": {"should": {"query": {"bool": {"should": [{"multi_match": {"query": "a2","operator": "or","fields": ["*.last"]}},{"match": {"last": "a2"}}]}}}}}}}}
8. 询条件添加以后,进行数量的检索_search?search_type=count
原文:http://www.cnblogs.com/ykkBlog/p/4667857.html
评论(0)