R语音读取txt报错:UTF-16不支持 或者<ff><fe><63>‘多字节字符串有错
时间:2021-06-04 14:23:46
收藏:0
阅读:17
1. 问题描述
一个txt文件,使用R中的data.table包中的fread函数读取时,报错:
>?dat?=?fread("test.txt")
Error?in?fread("test.txt")?:?
??File?is?encoded?in?UTF-16,?this?encoding?is?not?supported?by?fread().?Please?recode?the?file?to?UTF-8.使用read.table
>?dat?=?read.table("test.txt")
Error?in?type.convert.default(data[[i]],?as.is?=?as.is[i],?dec?=?dec,??:?
??‘‘多字节字符串有错
此外:?Warning?messages:
1:?In?read.table("test.txt")?:?line?1?appears?to?contain?embedded?nulls
2:?In?read.table("test.txt")?:?line?2?appears?to?contain?embedded?nulls
3:?In?read.table("test.txt")?:?line?3?appears?to?contain?embedded?nulls
4:?In?read.table("test.txt")?:?line?4?appears?to?contain?embedded?nulls
5:?In?read.table("test.txt")?:?line?5?appears?to?contain?embedded?nulls
6:?In?scan(file?=?file,?what?=?what,?sep?=?sep,?quote?=?quote,?dec?=?dec,??:
??embedded?nul(s)?found?in?input2. 问题解决
用notepad++查看了一下,编码形式:UCS-2
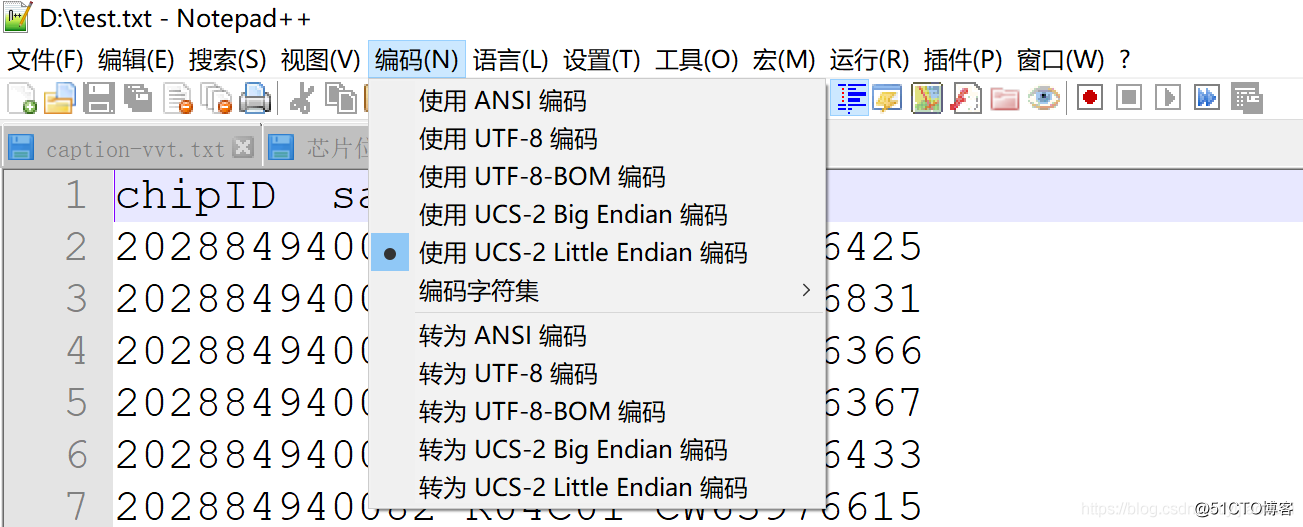
所以,在read.table中,设定编码形式:fileEncoding="UCS-2LE"
因此,修改后的代码为:
>?dat?=?read.table("test.txt",fileEncoding?=?"UCS-2",header?=?T)
>?head(dat)
???????????????chipID???sampleID
1?202884940082_R02C04?CW63976425
2?202884940082_R03C01?CW63976831
3?202884940082_R03C02?CW63976366
4?202884940082_R03C03?CW63976367
5?202884940082_R03C04?CW63976433
6?202884940082_R04C01?CW63976615搞定!。
3. 解决思路总结
查看文件的编码形式,用notepad++查看,然后定义编码的类型,使用read.table读取时,定义一下fileEncoding即可。以前我以为data.table包中的fread是万能的,没想到它给出报错不支持UTF-16,最后还是用基础包中的read.table解决了问题。
真香!
原文:https://blog.51cto.com/yijiaobani/2856299
评论(0)