(7)elasticsearch基本概念,elasticsearch基本原理
常用的搜索网站:百度、谷歌
数据的分类
结构化数据
指具有固定格式或有限长度的数据,如数据库,元数据等。对于结构化数据,我们一般都是可以通过关系型数据库(mysql、oracle)的table的方法存储和搜索,也可以建立索引。通过b-tree等数据结构快速搜索数据
非结构化数据
全文数据,指不定长或无固定格式的数据,如邮件,word等。对于非结构化数据,也即对全文数据的搜索主要有两种方式:顺序扫描法,全文搜索法
顺序扫描法
我们可以了解它的大概搜索方式,就是按照顺序扫描的方式查找特定的关键字。比如让你在一篇篮球新闻中,找出“科比”这个名字在那些段落出现过。那你肯定需要从头到尾把文章阅读一遍,然后标出关键字在哪些地方出现过
这种方式毋庸置疑是最低效的,如果文章很长,有几万字,等你阅读完这篇新闻找到“科比”这个关键字,那得花多少时间
全文搜索
对非结构化数据进行顺序扫描很慢,我们是否可以进行优化?把非结构化数据想办法弄得有一定结构不就好了嘛?将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对这些有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这种方式就构成了全文搜索的基本思路。这部分从非结构化数据提取出的然后重新组织的信息,就是索引。
什么是全文搜索引擎#
根据百度百科中的定义,全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每个词,对每个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户。
常见的搜索引擎#
Lucene#
- Lucene是一个Java全文搜索引擎,完全用Java编写。lucene不是一个完整的应用程序,而是一个代码库和API,可以很容易地用于向应用程序添加搜索功能
- 通过简单的API提供强大的功能
- 可扩展的高性能索引
- 强大,准确,高效的搜索算法
- 跨平台解决方案
- Apache软件基金会
- 在Apache软件基金会提供的开源软件项目的Apache社区的支持
- 但是Lucene只是一个框架,要充分利用它的功能,需要使用Java,并且在程序中集成Lucene。需要很多的学习了解,才能明白它是如何运行的,熟练运用Lucene确实非常复杂
Solr#
- Solr是一个基于Lucene的Java库构建的开源搜索平台。它以友好的方式提供Apache Lucene的搜索功能。它是一个成熟的产品,拥有强大而广泛的用户社区。它能提供分布式索引,复制,负载均衡以及自动故障转移和恢复。如果它被正确部署然后管理的好,他就能够成为一个高可用,可扩展且容错的搜索引擎
- 强大功能
- 全文搜索
- 突出
- 分面搜索
- 实时索引
- 动态集群
- 数据库集成
- NoSQL功能和丰富的文档处理
ElasticSearch#
- ElasticSearch是一个开源,是一个机遇Apache Lucene库构建的Restful搜索引擎
- ElasticSearch是Solr之后几年推出的。它提供了一个分布式,多租户能力的全文搜索引擎,具有HTTP Web页面和无架构JSON文档。ElasticSearch的官方客户端提供Java、Php、Ruby、Perl、Python、.Net和JavaScript
- 主要功能
- 分布式搜索
- 数据分析
- 分组和聚合
- 应用场景
- 维基百科
- Stack Overflow
- GitHub
- 电商网站
- 日志数据分析
- 商品价格监控网站
- BI系统
- 站内搜索
- 篮球论坛
ElasticSearch目录结构介绍
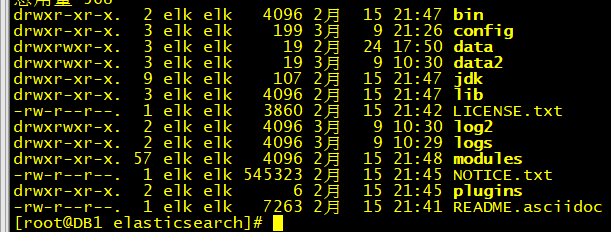
目录结构说明,在配置文件里操作使用
? home目录 :使用$ES_HOME表示,如上图,就是 /usr/local/elasticsearch
? bin/ : 位置 $ES_HOME/bin,包含了elasticsearch和elasticsearch-plugin等脚本
? conf/ :位置 $ES_HOME/config,包含了 配置文件 elasticsearch.yml 和 log4j2.properties,使用 path.conf 指定
? data/ :位置 $ES_HOME/data,包含了每个index/shard的数据文件,可以指定多个位置,使用 path.data 指定
? logs/ : 位置 $ES_HOME/logs,使用 path.logs 指定
? plguins/ : 位置$ES_HOME/plugins
? repo/ :使用 path.repo指定,没有默认位置,表示共享文件系统repository的位置。可以指定多个位置。
? script/ :位置$ES_HOME/scripts,使用 path.scripts 指定。
核心概念#
前言#
传统数据库查询数据的操作步骤是这样的:建立数据库->建表->插入数据->查询
索引(index)#
一个索引可以理解成一个关系型数据库
类型(type)#
一个type就像一类表,比如user表、order表
注意
1、ES 5.X中一个index可以有多种type
2、ES 6.X中一个index只能有一种type
3、ES 7.X以后已经移除type这个概念
映射(mapping)#
mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构
文档(document)#
一个document相当于关系型数据库中的一行记录
字段(field)#
相当于关系型数据库表的字段
集群(cluster)#
集群由一个或多个节点组成,一个集群由一个默认名称“elasticsearch”
节点(node)#
集群的节点,一台机器或者一个进程
分片和副本(shard)#
- 副本是分片的副本。分片有主分片(primary Shard)和副本分片(replica Shard)之分
- 一个Index数据在屋里上被分布在多个主分片中,每个主分片只存放部分数据
- 每个主分片可以有多个副本,叫副本分片,是主分片的复制
RESTful风格的介绍#
介绍#
- RESTful是一种架构的规范与约束、原则,符合这种规范的架构就是RESTful架构
- 先看REST是什么意思,英文Representational state transfer表述性状态转移,其实就是对资源的标书性状态转移,即通过HTTP动词来实现资源的状态扭转
- 资源是REST系统的核心概念。所有的设计都是以资源为中心
- elasticsearch使用RESTful风格api来设计的
方法#
| action | 描述 |
| HEAD | 只获取某个资源的头部信息 |
| GET | 获取资源 |
| POST | 创建或更新资源 |
| PUT | 创建或更新资源 |
| DELETE | 删除资源 |
GET /user:列出所有的?户 POST /user:新建?个?户 PUT /user:更新某个指定?户的信息 DELETE /user/ID:删除指定?户
调试工具:Postman工具(推荐)
原文:https://www.cnblogs.com/gered/p/14512699.html