hadoop_WordCount
时间:2020-11-13 18:28:25
收藏:0
阅读:32
按照mapreduce编程规范,分别编写Mapper,Reducer,Driver。
(1)定义一个mapper类
package com.atguigu.wordCount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /** * map阶段的业务逻辑就写在自定义的map()方法中 * maptask会对每一行输入数据调用一次我们自定义的map()方法 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 将maptask传给我们的文本内容先转换成String String line = value.toString(); // 2 根据空格将这一行切分成单词 String[] words = line.split(" "); // 3 将单词输出为<单词,1> for(String word:words){ // 将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reducetask中 context.write(new Text(word), new IntWritable(1)); } } }
(2)定义一个reducer类
package com.atguigu.wordCount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * KEYIN , VALUEIN 对应mapper输出的KEYOUT, VALUEOUT类型 * KEYOUT,VALUEOUT 对应自定义reduce逻辑处理结果的输出数据类型 KEYOUT是单词 VALUEOUT是总次数 */ public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * key,是一组相同单词kv对的key */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; // 1 汇总各个key的个数 for(IntWritable value:values){ count +=value.get(); } // 2输出该key的总次数 context.write(key, new IntWritable(count)); } }
(3)定义一个主类,用来描述job并提交job
package com.atguigu.wordCount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 相当于一个yarn集群的客户端, * 需要在此封装我们的mr程序相关运行参数,指定jar包 * 最后提交给yarn * @author Administrator */ public class WordcountDriver { public static void main(String[] args) throws Exception { // 1 获取配置信息,或者job对象实例 Configuration configuration = new Configuration(); // 8 配置提交到yarn上运行,windows和Linux变量不一致 // configuration.set("mapreduce.framework.name", "yarn"); // configuration.set("yarn.resourcemanager.hostname", "node22"); Job job = Job.getInstance(configuration); // 6 指定本程序的jar包所在的本地路径 // job.setJar("/home/admin/wc.jar"); job.setJarByClass(WordcountDriver.class); // 2 指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 3 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 4 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 5 指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 // job.submit(); boolean result = job.waitForCompletion(true); System.exit(result?0:1); } }
(4)将程序打成jar包,然后拷贝到hadoop集群中。
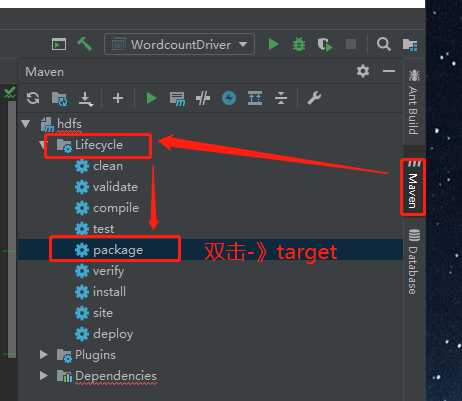
(5)启动hadoop集群
(6)执行wordcount程序
hadoop jar 1.jar com.atguigu.wordCount.WordcountDriver /README.txt /out
原文:https://www.cnblogs.com/hapyygril/p/13970733.html
评论(0)