pandas - 数据结构与常用函数
1. Pandas数据结构
-
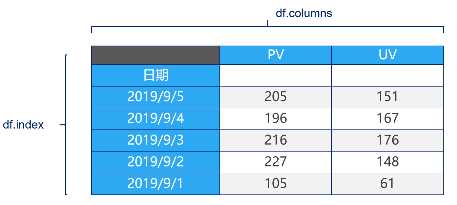
DataFrame: 二维数据,类似Excel或数据库表。
-
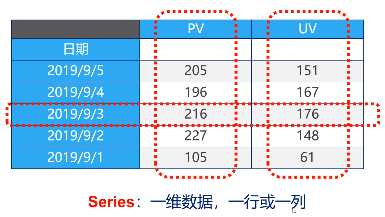
Series: 一维数据,既可以是一列,也可以是一行。处理方式类似于dict。
1.1. Series
1.1.1. 创建
注意,创建时需要数据值(value)及其索引 index(类似key)。
pd.Series([1, "a", 5.2, 7], index=["a", "b", "c", "d"])
## 2. 直接使用dict创建
pd.Series({"a": 1, "b": 2})
2. 访问数据
series["a"] = "new"
series[["a", "b"]] ## 查询多个值
2. 属性
- series.index ## np.ndarray
- series.values
- series.name ## values的name
- series.index.name ## index的name
2.1. DataFrame
Dataframe是一个表格型的数据结构
- 每列可以是不同的值类型(数值、字符串、布尔值等)
- 既有行索引 index,也有列索引 columns
- 可以被看由
Series组成的字典
创建 Datarame 最常用的方法,包括读取纯文本文件、excel、mysql数据库等。
基本使用:
-
使用多个字典序列创建DataFrame
data = { "state": ["a", "b", "c", "d"], "year": [2001, 2002, 2003, 2004], "pop": [1.6, 3.2, 7.9, 2.1] } df = pd.DataFrame(data) -
查询数据类型
df.dtypes -
查询列索引、行索引
df.columns df.index
2.1.1. 从DataFame中查询Series
- 如果只查询一行、一列,返回的是
pd.Series - 如果查询多行、多列,返回的是
pd.DataFrame
查询列
df["a"]
df[["a", "b"]]
查询行
df.loc[1]
df.loc[1:3] ## 通过切片的方式获取多行。注意:不同于list切片,loc[1:3]包含末尾元素`3`
2.2. 获取Pandas元素
需要认识到,pandas的索引方式,是有限索引行,然后再列。你无法做到loc某一列。如果非要,可以考虑直接提取Series,然后进行操作。
-
DataFrame.at
Access a single value for a row/column label pair.
-
DataFrame.iat
Access a single value for a row/column pair by integer position.
-
DataFrame.loc
Access a group of rows and columns by label(s).
-
DataFrame.iloc
Access a group of rows and columns by integer position(s).
>>> df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
... index=[‘cobra‘, ‘viper‘, ‘sidewinder‘],
... columns=[‘max_speed‘, ‘shield‘])
>>> df
max_speed shield
cobra 1 2
viper 4 5
sidewinder 7 8
## 3. 选取元素
>>> df.loc[‘cobra‘, ‘shield‘]
2
## 4. 选取行返回一个series
>>> df.loc[‘viper‘]
max_speed 4
shield 5
Name: viper, dtype: int64
## 5. 选取行列返回DataFrame
>>> df.loc[[‘viper‘, ‘sidewinder‘]]
max_speed shield
viper 4 5
sidewinder 7 8
With a callable, useful in method chains. The x passed to the lambda is the DataFrame being sliced. This selects the rows whose index label even.
>>> df.iloc[lambda x: x.index % 2 == 0]
a b c d
0 1 2 3 4
2 1000 2000 3000 4000
With a boolean array whose length matches the columns.
>>> df.iloc[:, [True, False, True, False]]
a c
0 1 3
1 100 300
2 1000 3000
5.1. 新增数据列
new_df = pd.concat([df, pd.DataFrame(columns=["h_low", "h_high", "s_low", "s_high", "v_low", "v_high"])])
new_df.h_low[idx] = 123 ## 数据赋值
5.2. 删除行或列
DataFrame.drop(labels=None,axis=0,index=None,columns=None, inplace=False)
参数说明:
- labels 就是要删除的行列的名字,用列表给定
- axis 默认为0,指删除行,因此删除columns时要指定axis=1
- index 直接指定要删除的行
- columns 直接指定要删除的列
- inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe
- inplace=True,则会直接在原数据上进行删除操作,删除后无法返回
因此,删除行列有两种方式:
- labels=None,axis=0的组合
- index或columns直接指定要删除的行或列
## 6. df=pd.read_excel(‘data_1.xlsx‘)
df=df.drop([‘学号‘,‘语文‘], axis=1)
df=df.drop([1,2], axis=0)
6.1. 保存当前的数据(序列化)
df2.to_csv("triage_new.csv")
7. 数据变换与预处理
常用函数如下
- DataFrame.head(), Series.head()
- DataFrame.info(), Series.info()
- DataFrame.describe(), Series.describe()
- Series.value_counts()
- DataFrame.sort_index(), Series.sort_index()
- DataFrame.sort_values(), Series.sort_values()
- 数据清洗
- DataFrame.isna(), Series.isna()
- DataFrame.any(), Series.any()
- DataFrame.dropna(), Series.dropna()
- DataFrame.fillna(), Series.fillna()
- Series.astype(), DataFrame.astype()
- DataFrame.rename(), Series.rename()
- DataFrame.set_index()
- Series.reset_index(), DataFrame.reset_index()
- DataFrame.drop_duplicates(), Series.drop_duplicates()
- DataFrame.drop(), Series.drop()
- DataFrame.isin(), Series.isin()
- pd.cut()
- pd.qcut()
- DataFrame.where(), Series.where()
- pd.concat()
- DataFrame.pivot_table()
用于演示的数据如下:
In [15]: data
Out[15]:
company salary age
0 NaN 43 21
1 A 8 41
2 A 28 26
3 C 42 28
4 A 33 26
5 C 20 18
6 A 48 43
7 B 25 23
8 B 39 18
-
DataFrame.head(), Series.head()
返回DataFrame的前N行。当数据量较大时,使用
.head()可以快速对数据有个大致了解。 -
DataFrame.info(), Series.info()
打印所用数据的一些基本信息,包括索引和列的数据类型和占用的内存大小。
data.info() <class ‘pandas.core.frame.DataFrame‘> RangeIndex: 9 entries, 0 to 8 Data columns (total 3 columns): company 8 non-null object salary 9 non-null int32 age 9 non-null int32 dtypes: int32(2), object(1) memory usage: 224.0+ bytes -
DataFrame.describe(), Series.describe()
主要用途:生成描述性统计汇总,包括数据的计数和百分位数,有助于了解大致的数据分布。
## 默认生成数值列的描述性统计 ## 使用 include = ‘all‘生成所有列 In [18]: data.describe() Out[18]: salary age count 9.000000 9.000000 mean 31.777778 27.111111 std 12.804079 9.143911 min 8.000000 18.000000 25% 25.000000 21.000000 50% 33.000000 26.000000 75% 42.000000 28.000000 max 48.000000 43.000000 -
Series.value_counts()
统计分类变量中每个类的数量,比如company中各个公司都有多少人
主要参数:
- normalize: boolean, default False, 返回各类的占比
- sort: boolean, default True, 是否对统计结果进行排序
- ascending: boolean, default False, 是否升序排列
In [19]: data[‘company‘].value_counts() Out[19]: A 4 B 2 C 2 Name: company, dtype: int64返回占比情况
In [20]: data[‘company‘].value_counts(normalize=True) Out[20]: A 0.50 B 0.25 C 0.25 Name: company, dtype: float64升序排列
In [21]: data[‘company‘].value_counts(ascending=True) Out[21]: C 2 B 2 A 4 Name: company, dtype: int64 -
DataFrame.sort_index(), Series.sort_index()
对数据按照索引进行排序
主要参数:
- ascending: boolean, default False, 是否升序排列
- inplace: boolean, default False, 是否作用于原对象
## 按索引降序排列 In [27]: data.sort_index(ascending=False) Out[27]: company salary age 8 B 39 18 7 B 25 23 6 A 48 43 5 C 20 18 4 A 33 26 3 C 42 28 2 A 28 26 1 A 8 41 0 NaN 43 21 -
DataFrame.sort_values(), Series.sort_values()
对DataFrame而言,按照某列进行排序(用by参数控制),对Series按数据列进行排序。
主要参数:
- by: str or list of str, 作用于DataFrame时需要指定排序的列
- ascending: boolean, default False, 是否升序排列
In [28]: data.sort_values(by=‘salary‘) Out[28]: company salary age 1 A 8 41 5 C 20 18 7 B 25 23 2 A 28 26 4 A 33 26 8 B 39 18 3 C 42 28 0 NaN 43 21 6 A 48 43 -
数据清洗
- DataFrame.isna(), Series.isna()
判断数据是否为缺失值,是的话返回True,否的话返回False
In [22]: data.isna() Out[22]: company salary age 0 True False False 1 False False False 2 False False False 3 False False False 4 False False False 5 False False False 6 False False False 7 False False False 8 False False False- DataFrame.any(), Series.any()
大多数情况下数据量较大,不可能直接isna()后一个一个看是否是缺失值。any()和isna()结合使用可以判断某一列是否有缺失值。
In [23]: data.isna().any() Out[23]: company True salary False age False dtype: bool- DataFrame.dropna(), Series.dropna()
删掉含有缺失值的数据。
In [24]: data.dropna() Out[24]: company salary age 1 A 8 41 2 A 28 26 3 C 42 28 4 A 33 26 5 C 20 18 6 A 48 43 7 B 25 23 8 B 39 18- DataFrame.fillna(), Series.fillna()
填充缺失数据
主要参数:
- value: scalar, dict, Series, or DataFrame, 用于填充缺失值的值
- method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None, 缺失值的充方式,常用的是bfill后面的值进行填充,ffill用前面的值进行填充
- inplace: boolean, default False, 是否作用于原对象
In [26]: data.fillna(‘B‘) Out[26]: company salary age 0 B 43 21 1 A 8 41 2 A 28 26 3 C 42 28 4 A 33 26 5 C 20 18 6 A 48 43 7 B 25 23 8 B 39 18用缺失值后面的值来填充(这里NaN后面是‘A‘)
In [25]: data.fillna(method=‘bfill‘) Out[25]: company salary age 0 A 43 21 1 A 8 41 2 A 28 26 3 C 42 28 4 A 33 26 5 C 20 18 6 A 48 43 7 B 25 23 8 B 39 18 -
Series.astype(), DataFrame.astype()
修改字段的数据类型,数据量大的情况下可用于减小数据占用的内存,多用于Series。
## 把age字段转为int类型 In [12]: data["age"] = data["age"].astype(int) In [13]: data Out[13]: company gender salary age 0 B female 30 40 1 A female 36 31 2 B female 35 28 3 B female 9 18 4 B female 16 43 5 A male 46 22 6 B female 15 28 7 B female 33 40 8 C male 19 32 -
DataFrame.rename(), Series.rename()
多用于修改DataFrame的列名
主要参数:
- columns: dict-like or function, 指定要修改的列名以及新的列名,一般以字典形式传入
- inplace: boolean, default False, 是否作用于原对象
## 将‘age‘更改为员工编号‘number‘,并作用于原对象 In [15]: data.rename(columns={‘age‘:‘number‘},inplace=True) In [16]: data Out[16]: company gender salary number 0 B female 30 40 1 A female 36 31 2 B female 35 28 3 B female 9 18 4 B female 16 43 5 A male 46 22 6 B female 15 28 7 B female 33 40 8 C male 19 32 -
DataFrame.set_index()
将DataFrame中的某一(多)个字段设置为索引
In [19]: data.set_index(‘number‘,inplace=True) In [20]: data Out[20]: company gender salary number 40 B female 30 31 A female 36 28 B female 35 18 B female 9 43 B female 16 22 A male 46 28 B female 15 40 B female 33 32 C male 19 -
Series.reset_index(), DataFrame.reset_index()
主要用途:重置索引,默认重置后的索引为0~len(df)-1
主要参数:
- drop: boolean, default False, 是否丢弃原索引,具体看下方演示
- inplace: boolean, default False, 是否作用于原对象
## drop = True,重置索引,并把原有的索引丢弃 In [22]: data.reset_index(drop=True) Out[22]: company gender salary 0 B female 30 1 A female 36 2 B female 35 3 B female 9 4 B female 16 5 A male 46 6 B female 15 7 B female 33 8 C male 19 ## drop = False,重置索引 ## 原索引列‘number‘作为新字段进入DataFrame In [23]: data.reset_index(drop=False,inplace=True) In [24]: data Out[24]: number company gender salary 0 40 B female 30 1 31 A female 36 2 28 B female 35 3 18 B female 9 4 43 B female 16 5 22 A male 46 6 28 B female 15 7 40 B female 33 8 32 C male 19 -
DataFrame.drop_duplicates(), Series.drop_duplicates()
主要用途:去掉重复值,作用和SQL中的distinct类似
In [26]: data[‘company‘].drop_duplicates() Out[26]: 0 B 1 A 8 C Name: company, dtype: object -
DataFrame.drop(), Series.drop()
主要用途:常用于删掉DataFrame中的某些字段
主要参数:
- columns: single label or list-like, 指定要删掉的字段
## 删掉‘gender‘列 In [27]: data.drop(columns = [‘gender‘]) Out[27]: number company salary 0 40 B 30 1 31 A 36 2 28 B 35 3 18 B 9 4 43 B 16 5 22 A 46 6 28 B 15 7 40 B 33 8 32 C 19 -
DataFrame.isin(), Series.isin()
主要用途:常用于构建布尔索引,对DataFrame的数据进行条件筛选
## 筛选出A公司和C公司的员工记录 In [29]: data.loc[data[‘company‘].isin([‘A‘,‘C‘])] Out[29]: number company gender salary 1 31 A female 36 5 22 A male 46 8 32 C male 19 -
pd.cut()
主要用途:将连续变量离散化,比如将人的年龄划分为各个区间
主要参数:
- x: array-like, 需要进行离散化的一维数据
- bins: int, sequence of scalars, or IntervalIndex, 设置需要分成的区间,可以指定区间数量,也可以指定间断点
- labels: array or bool, optional, 设置区间的标签
## 把薪水分成5个区间 In [33]: pd.cut(data.salary,bins = 5) Out[33]: 0 (23.8, 31.2] 1 (31.2, 38.6] 2 (31.2, 38.6] 3 (8.963, 16.4] 4 (8.963, 16.4] 5 (38.6, 46.0] 6 (8.963, 16.4] 7 (31.2, 38.6] 8 (16.4, 23.8] Name: salary, dtype: category Categories (5, interval[float64]): [(8.963, 16.4] < (16.4, 23.8] < (23.8, 31.2] < (31.2, 38.6] <(38.6, 46.0]] ## 自行指定间断点 In [32]: pd.cut(data.salary,bins = [0,10,20,30,40,50]) Out[32]: 0 (20, 30] 1 (30, 40] 2 (30, 40] 3 (0, 10] 4 (10, 20] 5 (40, 50] 6 (10, 20] 7 (30, 40] 8 (10, 20] Name: salary, dtype: category Categories (5, interval[int64]): [(0, 10] < (10, 20] < (20, 30] < (30, 40] < (40, 50]] ## 指定区间的标签 In [34]: pd.cut(data.salary,bins = [0,10,20,30,40,50],labels = [‘低‘,‘中下‘,‘中‘,‘中上‘,‘高‘]) Out[34]: 0 中 1 中上 2 中上 3 低 4 中下 5 高 6 中下 7 中上 8 中下 Name: salary, dtype: category Categories (5, object): [低 < 中下 < 中 < 中上 < 高] -
pd.qcut()
主要用途:将连续变量离散化,区别于pd.cut()用具体数值划分,pd.qcut()使用百分比进行区间划分
主要参数:
- x: array-like, 需要进行离散化的一维数据
- q: integer or array of quantiles, 置需要分成的区间,可以指定区间格式,也可以指定间断点
- labels: array or boolean, default None, 设置区间的标签
## 按照0-33.33%,33.33%-66.67%,66.67%-100%百分位进行划分 In [35]: pd.qcut(data.salary,q = 3) Out[35]: 0 (18.0, 33.667] 1 (33.667, 46.0] 2 (33.667, 46.0] 3 (8.999, 18.0] 4 (8.999, 18.0] 5 (33.667, 46.0] 6 (8.999, 18.0] 7 (18.0, 33.667] 8 (18.0, 33.667] Name: salary, dtype: category Categories (3, interval[float64]): [(8.999, 18.0] < (18.0, 33.667] < (33.667, 46.0]] -
DataFrame.where(), Series.where()
主要用途:将不符合条件的值替换掉成指定值,相当于执行了一个if-else
主要参数:
- cond: boolean Series/DataFrame, array-like, or callable, 用于筛选的条件
- other: scalar, Series/DataFrame, or callable, 对不符合cond条件的值(结果为为False),用other的值进行替代
## 语句解析 ## 若salary<=40,则保持原来的值不变 ## 若salary大于40,则设置为40 In [38]: data[‘salary‘].where(data.salary<=40,40) Out[38]: 0 30 1 36 2 35 3 9 4 16 5 40 6 15 7 33 8 19 Name: salary, dtype: int32 -
pd.concat()
主要用途:将多个Series或DataFrame拼起来(横拼或者竖拼都可以)
主要参数:
- objs: a sequence or mapping of Series or DataFrame objects, 用于拼接的Series或DataFrame,一般都放在一个列表中传入
- axis: 0/’index’, 1/’columns’, 控制数据是横向拼接还是纵向拼接,默认为纵向拼接。
- ignore_index: bool, default False, 是否保留原Seires或DataFrame内部的索引,如果为True则对拼接而成的数据生成新索引(0~n-1)
## 分别取data的前三条和后三条为data1和data2 In [41]: data1 = data.head(3) In [42]: data1 Out[42]: number company gender salary 0 40 B female 30 1 31 A female 36 2 28 B female 35 In [43]: data2 = data.tail(3) In [44]: data2 Out[44]: number company gender salary 6 28 B female 15 7 40 B female 33 8 32 C male 19 ## 拼接数据 In [45]: pd.concat([data1,data2],ignore_index = False) Out[45]: number company gender salary 0 40 B female 30 1 31 A female 36 2 28 B female 35 6 28 B female 15 7 40 B female 33 8 32 C male 19 ## 拼接数据并重置索引 In [46]: pd.concat([data1,data2],ignore_index=True) Out[46]: number company gender salary 0 40 B female 30 1 31 A female 36 2 28 B female 35 3 28 B female 15 4 40 B female 33 5 32 C male 19 -
DataFrame.pivot_table()
主要用途:对DataFrame进行数据透视,相当于Excel中的数据透视表
主要参数:
- values: column to aggregate, optional, 用于聚合运算的字段(数据透视的目标变量)
- index: column, Grouper, array, or list of the previous, 类比于数据透视表中的行标签
- columns: column, Grouper, array, or list of the previous, 类比于数据透视表中的列标签
- aggfunc: function, list of functions, dict, default numpy.mean, 对values进行什么聚合运算
## 从公司和性别两个维度对薪水进行数据透视 ## 看看这两个维度下的平均薪资水平 In [47]: data.pivot_table(values = ‘salary‘,index = ‘company‘, columns = ‘gender‘,aggfunc=np.mean) Out[47]: gender female male company A 36.0 46.0 B 23.0 NaN C NaN 19.0
8. 数据统计函数
Github: (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
本文就将针对pandas中的map()、apply()、applymap()、groupby()、agg()等方法展开详细介绍,并结合实际例子帮助大家更好地理解它们的使用技巧。
8.1. 数据载入
首先读入数据,这里使用到的全美婴儿姓名数据,包含了1880-2018年全美每年对应每个姓名的新生儿数据,在jupyterlab中读入数据并打印数据集的一些基本信息以了解我们的数据集:
import pandas as pd
## 9. 读入数据
data = pd.read_csv(‘data.csv‘)
data.head()
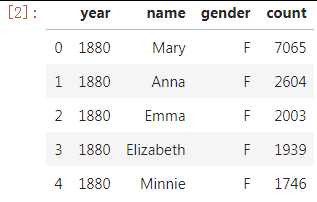
查看各列数据类型、数据框行列数
print(data.dtypes)
print()
print(data.shape)
9.1. 非聚合类方法(无需分组)
这里的非聚合指的是数据处理前后没有进行分组操作,数据列的长度没有发生改变,因此本章节中不涉及groupby()。
-
map()
字典映射
## 定义F->女性,M->男性的映射字典 gender2xb = {‘F‘: ‘女性‘, ‘M‘: ‘男性‘} ## 利用map()方法得到对应gender列的映射列 data.gender.map(gender2xb)映射函数
## 因为已经知道数据gender列性别中只有F和M所以编写如下lambda函数 data.gender.map(lambda x:‘女性‘ if x is ‘F‘ else ‘男性‘)特殊对象
## 一些接收单个输入值且有输出的对象也可以用map()方法来处理 data.gender.map("This kid‘s gender is {}".format)map()还有一个参数na_action,类似R中的na.action,取值为None或ingore,用于控制遇到缺失值的处理方式,设置为ingore时串行运算过程中将忽略Nan值原样返回。
-
apply()
apply()堪称pandas中最好用的方法,其使用方式跟map()很像,主要传入的主要参数都是接受输入返回输出。
但相较于map()针对单列Series进行处理,一条apply()语句可以对单列或多列进行运算,覆盖非常多的使用场景。
data.gender.apply(lambda x:‘女性‘ if x is ‘F‘ else ‘男性‘) ## 可以看到这里实现了跟map()一样的功能apply()最特别的地方在于其可以同时处理多列数据,我们先来了解一下如何处理多列数据输入单列数据输出的情况。
譬如这里我们编写一个使用到多列数据的函数用于拼成对于每一行描述性的话,并在apply()用lambda函数传递多个值进编写好的函数中(当调用DataFrame.apply()时,apply()在串行过程中实际处理的是每一行数据,而不是Series.apply()那样每次处理单个值)。
def generate_descriptive_statement(year, name, gender, count): year, count = str(year), str(count) gender = ‘女性‘ if gender is ‘F‘ else ‘男性‘ return f‘在{year}年,叫做{name}性别为{gender}的新生儿有{count}个。‘ ## 注意在处理多个值时要给apply()添加参数axis=1 data.apply(lambda row:generate_descriptive_statement(row[‘year‘], row[‘name‘], row[‘gender‘], row[‘count‘]), axis = 1)输出多列数据:有些时候我们利用apply()会遇到希望同时输出多列数据的情况,在apply()中同时输出多列时实际上返回的是一个Series,这个Series中每个元素是与apply()中传入函数的返回值顺序对应的元组。
比如下面我们利用apply()来提取name列中的首字母和剩余部分字母:
data.apply(lambda row: (row[‘name‘][0], row[‘name‘][1:]), axis=1)可以看到,这里返回的是单列结果,每个元素是返回值组成的元组,这时若想直接得到各列分开的结果,需要用到zip(*zipped)来解开元组序列,从而得到分离的多列返回值:
a, b = zip(*data.apply(lambda row: (row[‘name‘][0], row[‘name‘][1:]), axis=1)) print(a[:10]) print(b[:10]) -
applymap()
applymap()是与map()方法相对应的专属于DataFrame对象的方法,类似map()方法传入函数、字典等,传入对应的输出结果。
不同的是applymap()将传入的函数等作用于整个数据框中每一个位置的元素,因此其返回结果的形状与原数据框一致。
譬如下面的简单示例,我们把婴儿姓名数据中所有的字符型数据消息小写化处理,对其他类型则原样返回:
def lower_all_string(x): if isinstance(x, str): return x.lower() else: return x data.applymap(lower_all_string)
9.2. 聚合类方法
有些时候我们需要像SQL里的聚合操作那样将原始数据按照某个或某些离散型的列进行分组再求和、平均数等聚合之后的值,在pandas中分组运算是一件非常优雅的事。
9.2.1. 利用groupby()进行分组
要进行分组运算第一步当然就是分组,在pandas中对数据框进行分组使用到groupby()方法。
其主要使用到的参数为by,这个参数用于传入分组依据的变量名称,当变量为1个时传入名称字符串即可。
当为多个时传入这些变量名称列表,DataFrame对象通过groupby()之后返回一个生成器,需要将其列表化才能得到需要的分组后的子集,如下面的示例:
## 10. 按照年份和性别对婴儿姓名数据进行分组
groups = data.groupby(by=[‘year‘,‘gender‘])
## 11. 查看groups类型
type(groups)
可以看到它此时是生成器,下面我们用列表解析的方式提取出所有分组后的结果:
## 12. 利用列表解析提取分组结果
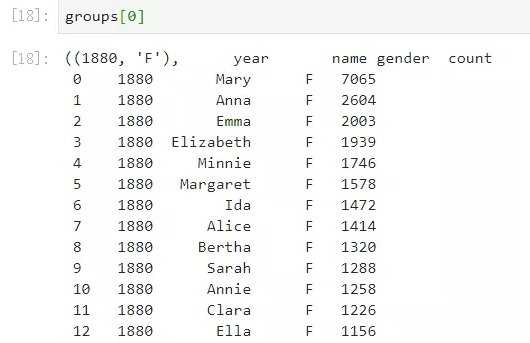
groups = [group for group in groups]
查看其中的一个元素,可以看到每一个结果都是一个二元组,元组的第一个元素是对应这个分组结果的分组组合方式,第二个元素是分组出的子集数据框,而对于DataFrame.groupby()得到的结果。
直接调用聚合函数
譬如这里我们提取count列后直接调用max()方法:
## 13. 求每个分组中最高频次
data.groupby(by=[‘year‘,‘gender‘])[‘count‘].max()
注意这里的year、gender列是以索引的形式存在的,想要把它们还原回数据框,使用reset_index(drop=False)即可:
data.groupby(by=[‘year‘,‘gender‘])[‘count‘].max().reset_index(drop=False)
结合apply()
分组后的结果也可以直接调用apply(),这样可以编写更加自由的函数来完成需求,譬如下面我们通过自编函数来求得每年每种性别出现频次最高的名字及对应频次。
要注意的是,这里的apply传入的对象是每个分组之后的子数据框,所以下面的自编函数中直接接收的df参数即为每个分组的子数据框:
import numpy as np
def find_most_name(df):
return str(np.max(df[‘count‘]))+‘-‘+df[‘name‘][np.argmax(df[‘count‘])]
data.groupby([‘year‘,‘gender‘]).apply(find_most_name).reset_index(drop=False)
13. 利用agg()进行更灵活的聚合
agg即aggregate,聚合,在pandas中可以利用agg()对Series、DataFrame以及groupby()后的结果进行聚合。
其传入的参数为字典,键为变量名,值为对应的聚合函数字符串,譬如 {‘v1‘:[‘sum‘,‘mean‘], ‘v2‘:[‘median‘,‘max‘,‘min]} 就代表对数据框中的v1列进行求和、均值操作,对v2列进行中位数、最大值、最小值操作。
下面用几个简单的例子演示其具体使用方式:
聚合Series
在对Series进行聚合时,因为只有1列,所以可以不使用字典的形式传递参数,直接传入函数名列表即可:
## 14. 求count列的最小值、最大值以及中位数
data[‘count‘].agg([‘min‘,‘max‘,‘median‘])

聚合数据框
对数据框进行聚合时因为有多列,所以要使用字典的方式传入聚合方案:
data.agg({‘year‘: [‘max‘,‘min‘], ‘count‘: [‘mean‘,‘std‘]})
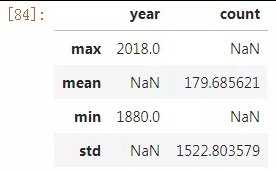
值得注意的是,因为上例中对于不同变量的聚合方案不统一,所以会出现NaN的情况。
聚合groupby()结果
data.groupby([‘year‘,‘gender‘]).agg({‘count‘:[‘min‘,‘max‘,‘median‘]}).reset_index(drop=False)
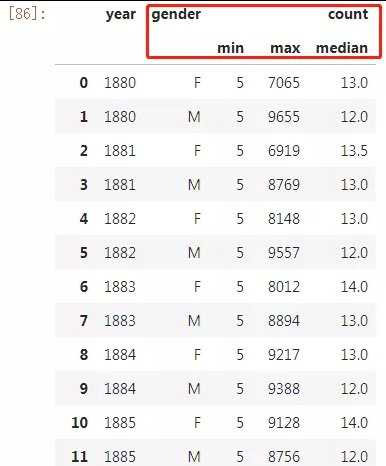
可以注意到虽然我们使用reset_index()将索引列还原回变量,但聚合结果的列名变成红色框中奇怪的样子,而在pandas 0.25.0以及之后的版本中,可以使用pd.NamedAgg()来为聚合后的每一列赋予新的名字:
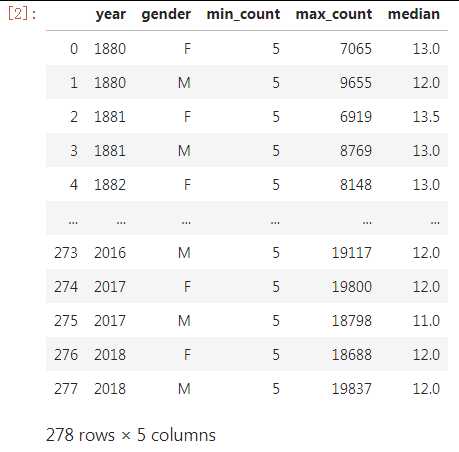
data.groupby([‘year‘,‘gender‘]).agg(
min_count=pd.NamedAgg(column=‘count‘, aggfunc=‘min‘),
max_count=pd.NamedAgg(column=‘count‘, aggfunc=‘max‘),
median=pd.NamedAgg(column=‘count‘, aggfunc=‘median‘)).reset_index(drop=False)
14.1. groupby 详解
df.groupby("A").sum()
df.groupby(["A", "B"]).mean()
df.groupby(["A", "B"], as_index=False).mean()
df.groupby("A").agg([np.sum, np.mean, np.std])
df.groupby("A")["C"].agg([np.sum, np.mean, np.std])
df.groupby("A").agg([np.sum, np.mean, np.std])["C"] ## 同上
df.groupby("A").agg({"C": np.sum, "D": np.maen})
14.1.1. GroupBy遵从split、apply、combine模式

14.1.2. 归一化:电影评分
def normalize(df):
min_value = df["Rating"].min()
max_value = df["Rating"].max()
df["Rating_norm"] = df["Roting"].apply(
lambda x: (x-min_value)/(max_value-min_value))
return df
def top_2(df, n=2):
return df.sort_values(by="Rating")[[]]
df.groupby("manth").apply(get_)
原文:https://www.cnblogs.com/brt2/p/13466166.html