Spark Streaming消费KafKa数据 demo
时间:2020-08-05 00:30:07
收藏:0
阅读:97
1.首先模拟一个生产者不断的向Kafka灌数据
package com.program.KafkaToSparkStreaming import java.util.Properties import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord} import scala.util.Random /** * Created by jihn88 on 2020/8/1. */ object Producer extends App{ //从运行时参数读入topic val topic = "test0307" //从运行时参数读入brokers val brokers = "node1:9092,node2:9092,node3:9092" //设置一个随机数 val random = new Random() //配置参数 val prop = new Properties() //配置brokers prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokers)
//序列化类型 prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer") prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer") //建立Kafka连接 val kafkaProducer = new KafkaProducer[String,String](prop) val t = System.currentTimeMillis() //模拟用户名地址数据 val nameAddrs = Map("bob"->"shanghai#200000", "amy"->"beijing#100000", "alice"->"shanghai#200000", "tom"->"beijing#100000", "lulu"->"hangzhou#310000", "nick"->"shanghai#200000") //模拟用户名电话数据 val namePhones = Map( "bob"->"15700079421", "amy"->"18700079458", "alice"->"17730079427", "lulu"->"18800074423", "nick"->"14400033426" ) for(nameAddr <- nameAddrs){ val data = new ProducerRecord[String,String](topic,nameAddr._1, s"${nameAddr._1}\t${nameAddr._2}\t0") //数据写入Kafka kafkaProducer.send(data) if(random.nextInt(100)<50) Thread.sleep(random.nextInt(10)) } for(namePhone<- namePhones){ val data = new ProducerRecord[String,String](topic,namePhone._1, s"${namePhone._1}\t${namePhone._2}\t1") kafkaProducer.send(data) if(random.nextInt(100)<50) Thread.sleep(random.nextInt(10)) } System.out.println("Send peer second:"+(nameAddrs.size+namePhones.size)*1000/ (System.currentTimeMillis()-t)) //生成模拟数据 (name,addr,type:0) kafkaProducer.close() }
2.建立Spark Streaming连接Kafka消费Kafka数据
package com.program.KafkaToSparkStreaming import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe /** * Created by jihn88 on 2020/8/1. */ object KafkaSparkStreaming extends App{ val conf = new SparkConf(). setMaster("local") .setAppName("kafkaSparkStreaming") .set("spark.streaming.kafka.MaxRatePerPartition","3") .set("spark.local.dir","./tmp") //创建上下文,2s为批处理间隔 val ssc = new StreamingContext(conf,Seconds(10)) //设置日志级别 ssc.sparkContext.setLogLevel("ERROR") //配置kafka参数,根据broker和topic创建连接Kafka 直接连接 direct kafka val KafkaParams = Map[String,Object]( //brokers地址 "bootstrap.servers"->"node1:9092,node2:9092,node3:9092", //序列化类型 "key.deserializer"->classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "MyGroupId", //设置手动提交消费者offset "enable.auto.commit" -> (false: java.lang.Boolean)//默认是true ) //获取KafkaDStream val kafkaDirectStream = KafkaUtils.createDirectStream[String,String](ssc, //test0307为topic PreferConsistent,Subscribe[String,String](List("test0307"),KafkaParams)) //根据得到的kafak信息,切分得到用户电话DStream val nameAddrStream = kafkaDirectStream.map(_.value()).filter(record=>{ val tokens: Array[String] = record.split("\t") tokens(2).toInt==0 }).map(record=>{ val tokens = record.split("\t") (tokens(0),tokens(1)) }) val namePhoneStream = kafkaDirectStream.map(_.value()).filter( record=>{ val tokens = record.split("\t") tokens(2).toInt == 1 } ).map(record=>{ val tokens = record.split("\t") (tokens(0),tokens(1)) }) //以用户名为key,将地址电话配对在一起,并产生固定格式的地址电话信息 val nameAddrPhoneStream = nameAddrStream.join(namePhoneStream).map( record=>{ s"姓名:${record._1},地址:${record._2._1},邮编:${record._2._2}" } ) //打印输出 nameAddrPhoneStream.print() //开始计算 ssc.start() ssc.awaitTermination() }
最后输出信息如下
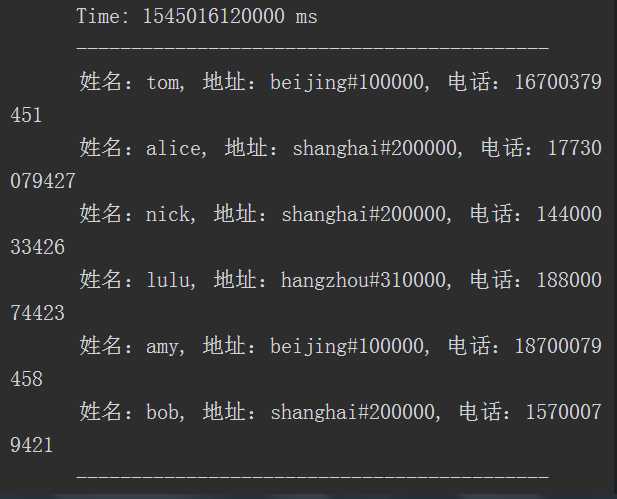
原文:https://www.cnblogs.com/itachilearner/p/13436909.html
评论(0)