RIP距离矢量路由协议
RIP 动态路由协议(已过时)
距离矢量路由协议
根据跳数决定最优路径(是一个已经被需求所淘汰的协议,但为什么还要学习呢?因为和后面的BGP有些许的相像)
无论是静态路由协议还是动态路由协议,
其目的只有一个,就是构建一张最优的路由表。
RIP的版本
RIPv1
使用广播更新,这是很不理想的,因为不运行rip协议的设备,尤其是终端设备,同样会收到这样的更新,而他们本身也不是路由设备,根本就不需要,所以无形中浪费带宽。
RIP v2
引用了组播的概念,使用的地址是224.0.0.9,这样一来,可以很大限度的去限制流量的浪费,
组播,其实说白话讲,就是将一些设备定义到一个组,你只给这个组的人发信息,而组外的人是收不到的,这时的组播就是这个意思,只有运行了相同协议的设备,才算是进组,才可以监听这个信息。
RIP特性,为什么会被淘汰
跳数限制
这个协议是早期出现的,是无法满足现在的网络环境的,
有三点,
其一:根据跳数的限制,RIP最大只支持15跳,16跳就是不可达,
不能适用于大型的网络(每经过一个路由设备为一跳),其实15跳也还可以了,
其二:它只会选择跳数最少的为最优路径,不会去考虑带宽,
其三:RIP的收敛时间那是相当的漫长的
RIP 的管理距离
[120/1]
120:RIP协议的管理路由,系统自定,无法修改
1:度量值,协议的链路标准(跳数)
路由协议三大标准
决定一个路由协议的好坏,无外乎三个标准 :
选路标准
如何更新
如何收敛
1选路标准
上面也提到了,RIP只根据跳数来决定最优路径
如图所示:
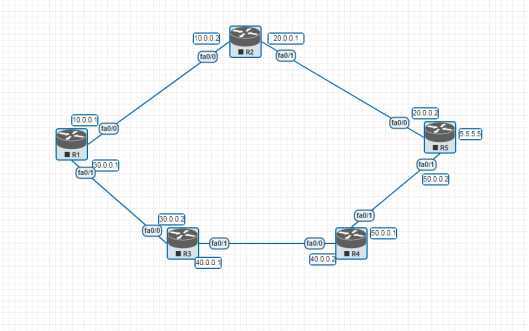
R1想要访问R5,假设上面的链路带宽为10M,而下面的带宽为1G,那么在RIP协议中会被忽视,因为只认跳数,从上面的链路上看,只经过了一跳,而现在的链路会经过三跳
所以RIP 会选择上面的链路。
2如何更新
224.0.0.9 30S更新一次
RIP v2版本使用组播更新,这也是一个突破 ,因为在V1版本的时候使用的是广播,
那就要明白都有哪些更新的方式
-1 单播 --
(单独给每一个人都发一份,其缺点就是浪费带宽,消耗资源,因为每人都要发一次)
-2 广播
(任何人都能收到,这会使不想收到的人也能看到,没有意思,浪费)
-3 组播
(只发给想要收到这个消息的人,等于是建立了一个组)
只发给运行了rip协议的设备,
3如何收敛
(就是当主线路故障之后,备选线路多长时间能够启用)
最长240S
180S的死亡时间+60S的刷新时间
在180S的时候会将该路由条目标记为“可能down”状态 possibly down
再最后等60S的确认时间,如果还没有活过来,那就直接DOWN,删除这个条目。然后重新选路,再切换到备用线路
RIP的配置
1) 启用rip
2) 修改版本
3) 关闭自动汇总
4) 宣告网段 (RIP不支持VLSM)
宣告网段,就是把和对端设备相连的接口网段宣告出去,再加上自己的其它接口网段
版本有两个v1\v2,通常情况下,我们都用v2版本
关闭自动汇总,为什么?
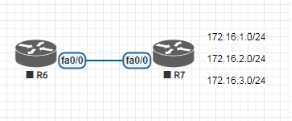
如上图所示,如果没有关闭路由自动汇总,那么默认情况下,R7所宣告出来的网段就会被显示成172.16.0.0/16,会根据主类地址进行汇总,如/8./16./24 ,
这样有什么不好吗?
好处是可以缩小路由表的大小,
坏处,就是会产生路由黑洞!
路由黑洞的形成,
假设现在R6收到访问172.16.4.0/24,请问可以发出去吗?根据172.16.0.0/16的路由条目是可以发过去的,但是R7收到数据后,查看自己的路由条目没有去往172.16.4.0/24的目标地址,就会进行丢弃,
R6这边一直发,R7这边一直丢,这就形成了路由黑洞,数据是有去无回的
路由汇总不是不好,但是我们一般不要自动汇总,我们都是要手动汇总的
配置:
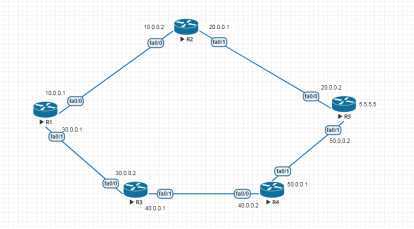
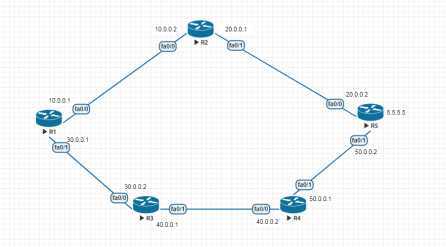
全网运行RIPv2
配置IP不在赘述
R1
r1(config)#router rip ///启用RIP协议
r1(config-router)#version 2 ////版本2
r1(config-router)#no auto-summary ///关闭路由自动汇总
r1(config-router)#network 10.0.0.0 //宣告网段
r1(config-router)#network 30.0.0.0 //因为有两个接口,所以要宣告两个
R2,R3,R4都一样,
R5
r5(config)#router rip
r5(config-router)#version 2
r5(config-router)#no auto-summary
r5(config-router)#network 50.0.0.0
r5(config-router)#network 20.0.0.0
r5(config-router)#network 5.5.5.0 //这里启用了一个环回口,模拟其它网段
然后用R1去PING 5.5.5.5 是通的,但是现在要看的是究竟走的哪边
根据RIP的选路原则,肯定是选择上面的,因为上面的跳数少
我们在R2的F0/0口上进行抓包,看看有没有数据经过

可以看到 原10.0.0.1 目的5.5.5.5的icmp包,以及源目对调的ICMP reply包,
说明我们的判断没有问题,
那在R3的接口上可以找到这样的包吗?

显然是没有的,
在这里,只能看到224.0.0.9的更新数据
分析路由表
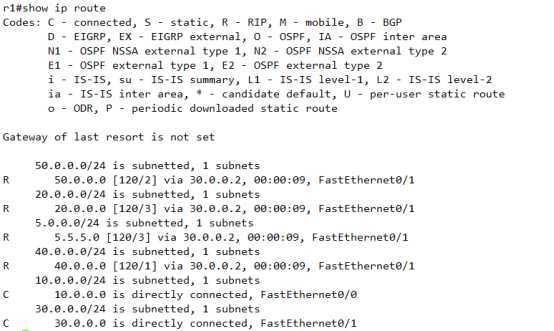
这里只用看R1的,5.5.5.5条目

其中表明
5.0.0.0/24 is subnetted, 1 subnets
R 5.5.5.0 [120/2] via 10.0.0.2, 00:00:09, FastEthernet0/0
目的网段 [管理距离/度量值] via下一跳 时间计时器 本设备出接口
现在我们模拟R2的f0/0接口down掉,也就是上面的链路走不通了,看RIP多长时间能够收敛完成
时间真的很漫长,先要经过180S的死亡时间,然后再经过 60S的刷新时间,才能够正确的激活,
我们来看一下,这里的切图只切5.5.5.5这条了 
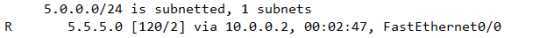
时间一点一点的过,180S =3分钟
那么过了3分钟会是什么样呢?

RIP会认为这个条目有可能DOWN,显示为possibly down
此时,肯定也是ping不通的

再过一会这些条目将会被删除,

原有去往5.5.5.0的路由条目被删除了,
因为RIP 经过 240S 的收敛时间,就真的认为它已经死了
在这之后,开始重新选路,
5.5.5.0网段的条目又出来了,
测试Ping

在R3上抓包,结果可想而之,肯定是有的

好像除了慢点儿没有别的问题
需要注意一个细节,
之前的去往5.5.5.5的条目是这样的
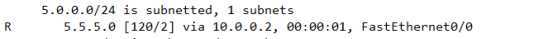
新的条目是这样儿的

有什么变化吗?
[120/2] [120/3],度量值发生了变化
原来从R1到达5.5.5.5只需要2跳所以被选为最优路径显示在路由表中
而现在因为原最优线路故障,导致重新收敛,新的线路需要经过3跳才可以到达,而且这条路还是仅有的,想要到达5.5.5.5,不走这里也没办法了。
RIP的高级设置
Rip认证
无论是哪种路由协议,只要是动态路由协议,都会涉及到加密,为什么要加密呢?
其实不光是加密,而且一定标准下,密码还要定期更换,
主要是为了防止携带有相同密码的设备接入网络后影响原有网络拓扑环境。这个很致命的。

明文
思路
1定义钥匙名称
2定义钥匙号
3定义具体的密码
4接口挂接
命令
R1(config)#key chain 11 //钥匙名称,为后面的调用做准备
R1(config-keychain)#key 1 //钥匙号,两边要保证一样
R1(config-keychain-key)#key-string 123 //具体的密码,这里设置的为123
R1(config-keychain-key)#exit
R1(config-keychain)#exit
R1(config)#inter f0/0
R1(config-if)#ip rip authentication key-chain 11 //进入接口下调用。
R2(config)#key chain 11
R2(config-keychain)#key 1
R2(config-keychain-key)#key-string 123
R2(config-keychain-key)#exit
R2(config-keychain)#exit
R2(config)#inter f0/0
R2(config-if)#ip rip authentication key-chain 11
两端要保证一致,如果是明文就都是明语言,如果是密码就都是密文,否则无法接到对方过来的条目。
配置完以后,如何查看具体的配置呢?
R2#show run | se key
key chain 11
key 1
key-string 123
R2#show run | se authen
ip rip authentication key-chain 11
密文
R1(config-if)#ip rip authentication mode md5
R2(config-if)#ip rip authentication mode md5
只要在后面加上一个mode md5即可
查看还是一样的命令
R2#show run | se authen
ip rip authentication mode md5
ip rip authentication key-chain 11
密文的配置思路和明文的一样,只是在最后加一个加密的方式。
负载均衡
等价,默认就是等价的,但通 常不是我们想要的
偏移列表
Offse-list 当去往同一个目的地,出现两个不同下一跳的路径时,会出负载均衡的情况,
可如果此时我想要人为的控制其走向,怎么办呢?
可以通过offset-list
其原理就是通过ACL来抓取相应的路由,再利用offset-list来对这个方向的路由进行metric进行控制,(增加)【之前我们一直提到,RIP的选路很单纯,只有一个,那就是跳数,越少越优,如果人为的将这个条目来给加大,那也就成为了次优,从而影响它的选路】
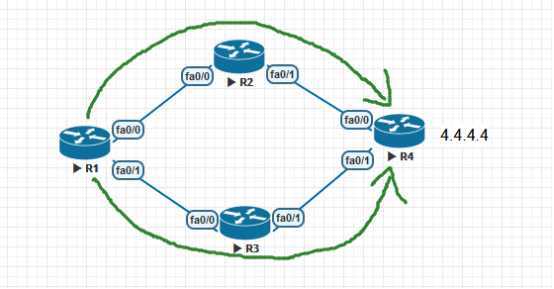
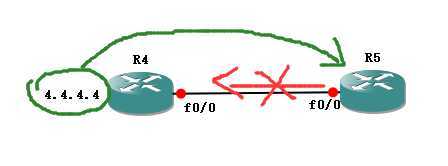
如图所未,R1去往4.4.4.4的路径肯定是有两条的,12.0.0.2 /13.0.0.3,
需求:要求首选13.0.0.3,次选12.0.0.2 ,也可以说当R3这边的链路故障时,可以进行路径切换,实现冗余备份的目的。
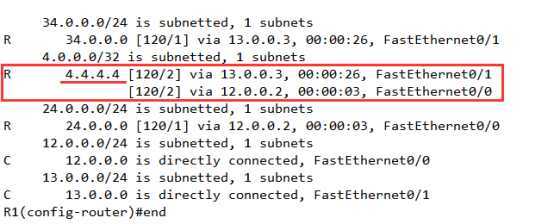
先是用ACL来抓取具体的条目,(切记,条目的抓取要按照路由表中显示的样子来【是字母后面的样式】,它写成什么样,你就写什么样)
R1(config)#access-list 1 permit 4.4.4.4
一使用offset-list进行调用
R1(config-router)#offset-list 1 in 5 f0/0
针对于acl列表1的条目,in方向,加5个metric 在f0/0接口上。
在这里解读一下什么是in 什么是out
这取决于路由的传递方向,
4.4.4.4 本是R4的路由,传递到R1,做为R1而言这个条目是进来的,所以是in
而如果在R4看来,4.4.4.4这个条目是自己的,是发出去的,所以是OUT
【这个一定要搞清楚,不然到后面的distribute是无法弄明白的】
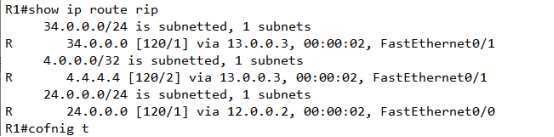
这样一台,就只剩下一个了,VIA为13.0.0.3
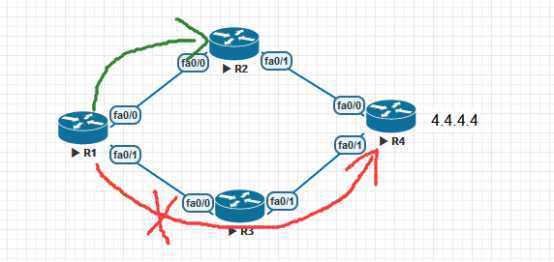
此时模拟R3这边的链路DOWN掉,就可以直接跳转到R2上了,
R1(config)#inter f0/1
R1(config-if)#shu
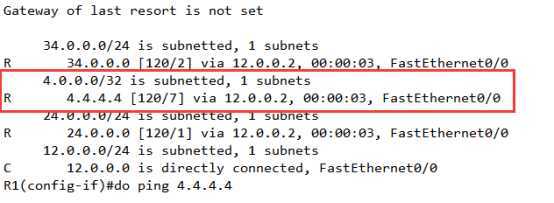
达到效果
额外赠送一个小实例
自己动动手,看看仅通过offset-list这项技术能否达到效果
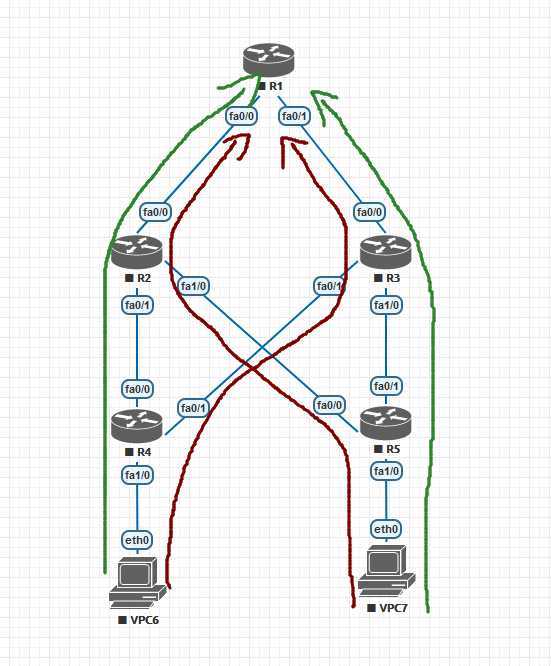
要求绿色为首选,红色为备选
只使用一种offset-list,偏移列表来实现,来验证你的学习成果。
分发列表
Distribute-lis,这个在后面的eigrp,OSPF中都会用到,
通俗讲这项技术就是给与不给,收与不收的做用,
啥意思?说人话
就是我有很多条目,可以做选择性的传递和接收
还是需要和ACL相结合
ACL+distribute-list
ACL起决策作用
distribute-list负责调用acl,确切的说应该是部署
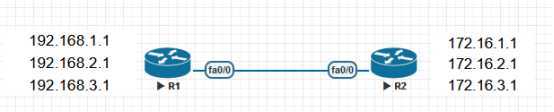
需求:
使用分发列表,r1在发而时不发布192.168.2.1
R2在接收时不拒收192.168.3.1
R1接收来自R2的条目时,只接收172.16.1.1
基本配置不再赘述了
需要1
R1(config)#access-list 1 deny 192.168.2.0
R1(config)#access-list 1 permit any
R1(config)#router rip
R1(config-router)#distribute-list 1 out
R2查看结果(要等待RIP的收敛时间,很漫长)
需求2
R2(config)#access-list 1 deny 192.168.3.0
R2(config)#access-list 1 per any
R2(config)#router rip
R2(config-router)#distribute-list 1 in
R2查看结果

需求3
R1(config)#access-list 2 per 172.16.1.0 //因为ACL有默认的DENY ANY,所以只允许了一条,其它全都拒绝,偷懒小技巧
R1查看结果

路由汇总
RIP不是有自动汇总嘛,为什么不用呢?还想着手动汇总
因为自动汇总后会产生路由黑洞,
路由黑洞,转发现去的数据直接被丢到“黑洞”这是一个未知的世界,里面什么都没有,也没有人会给你回应,反应在设备上就是丢包,数据被转发,但是没有回应。
RIP的汇总有一个关键性的限制,那就是CIDR不支持,
VLSM,可变长子网掩码,
CIDR,超网,
啥是CIDR,
举个栗子,192.168.1.0/24是一个C类的网段,如果将这个表示为192.168.0.0/20
那这个就叫超网,越过其原有主类的形式汇总,就叫超网汇总,RIP是不支持的,
怎么说呢,这个事儿,其实也很好理解,在RIP宣告网段的时候就能看出来,只能按主类进行宣告,
那又如何操作呢?
实例(路由设备还是用gns3比较爽)省资源(可是哥也不差你那点内存)
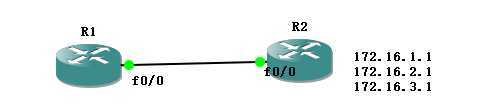
在R2上的F0/0接口上做汇总,
没有汇总之前R1看路由表是这样的

R2(config-if)#ip summary-address rip 172.16.0.0 255.255.0.0 //只能按主类进行汇总
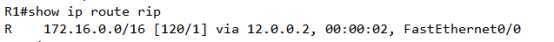
R1上此时看到的就是172.16.0.0/16
???这么看和auto-summary有什么区别吗?好像区别并不大,
如果你看到这里,请记得给我回复,我是真没找出来有什么不同,
而且也亲自都测试了一下
单播路由
单手路由?RIPv2版本不是使用的组播吗?为什么这里又出现了一个单播?
这东西干啥用的?
其实你可以这样理解,它的出现,就是为了解决RIP的水平分割问题的
RIP的水平分割,从这个接口收到的路由,至死都不会从这个接口再传出去。
基本情况
下面再来看一个有意思的测试
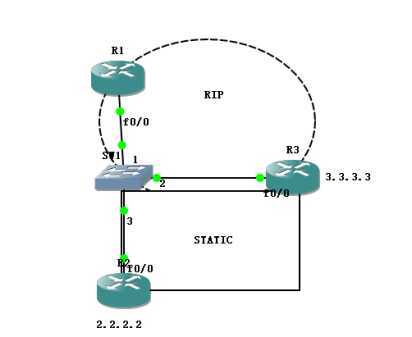
R1-R3之间运行RIP
R2-R3之间运行STATIC,然后由R3将STATIC重发布进RIP,
请问R1能否收到2.2.2.2的路由条目?
答案是肯定不可以的,为什么?这就是因为RIP的水平分割原则,
因为路由是从F0/0接口学习进来的,不可能再从这里发布出去,RIP认为有环路,
那么现在我就让你发,你就得发,怎么办?使用单播路由,
指定邻居
R3(config)#ip route 2.2.2.0 255.255.255.0 10.0.0.2
R3(config)#router rip
R3(config-router)#redistribute static metric 1
R3(config-router)#passive-interface f0/0 //改变接口为被动接口
R3(config-router)#neighbor 10.0.0.1 //指定邻居为R1

R1收到了这个条目,但是你有没有发现这里的VIA是R2,并非R3 ,这是为什么呢?
值得你去思考一下。
默认路由
由上游设备向下游设备下发默认路由,而不用去手动配置,一定程度上可以减轻配置压力,
另外,最主要的,由于是动态路由,还可以产生联动,当上面出现问题时,下面的默认路由也将不复存在。
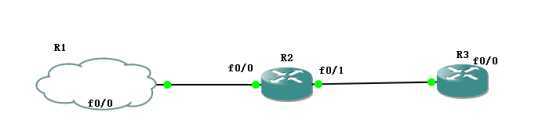
R2做这作为出口网关设备,下连R3,之间运行RIP协议
在R2上配置NAT,
由R2下发一条默认路由,给R3,
(如果是手动在R3上配置可不可行吗?当然可行,但不好,不会出现联动)
NAT部分不说明
R2(config-if)#inter f0/0
R2(config-if)#ip nat ou
R2(config-if)#inter f0/1
R2(config-if)#ip nat in
R2(config)#ip route 0.0.0.0 0.0.0.0 12.0.0.1
R2(config)#access-list 1 per any
R2(config)#ip nat in so li 1 inter f0/0 overload
R2(config-router)#default-information originate
R3(config-router)#do show ip route rip
R* 0.0.0.0/0 [120/1] via 23.0.0.2, 00:00:05, FastEthernet0/0
此时,在R3上可以看到下一跳为23.0.0.2(R2)的0.0.0.0默认路由,且为R*,这和普通的R路由有所不同。
之前咱们提到过,如果上面的默认路由出现问题,这里也会消失,
我们将GW上和ISP相连的接口DOWN掉,看看这边还在不在
R2(config-router)#inter f0/0
R2(config-if)#shu

刷了几次,依然是没有的,看来是起做用了。
----------------------------------------------------------
CCIE成长之路 --- 梅利
原文:https://www.cnblogs.com/meili333/p/13297286.html