浅谈日志收集
时间:2020-06-26 16:59:07
收藏:0
阅读:84
前言
各种程序输出的日志重要性不言而喻,借助日志可以分析程序的运行状态、用户的操作行为等。最早常说的日志监控系统是ELK,即ElasticSearch(负责数据检索)、Logstash(负责数据收集)、Kibana(负责数据展示)三个软件的组合,随着技术的发展,又出现了很多新的名词,比如EFK,这个F可以指Filebeat,有时也指Fluentd,其实日志收集软件的原理都是大概相同的,区别是它们的编程语言不同,功能不同,所以在选择时要根据自己的实际情况,比如在K8S及docker环境中,就可以使用更轻量级的fluent-bit, 而在云虚拟机和物理机上,则可以使用功能更强大的fluentd,目前我一直在线上使用fluentd系列的软件来收集日志,而且它们在长期的线上环境上运行良好。
实际上有时候我们并不需要ELK(或者EFK)的全部功能,比如出于成本考虑,只需要把多台机器上(或者容器)中的日志汇总到一台专用的日志机器上,并通过日期和目录区分,就已经方便技术人员登录查看,这样就节省了ES和Kibana的资源,当然这只是省钱的方法。后面的内容将写到完整的日志收集场景和配置方法。
场景1:从多台云主机收集日志到统一的Logserver
由于对fluentd比较熟悉了,我们这里的操作就使用Fluentd来实现,原理是Fluentd在AppServer上tail日志文件,并将产生的内容发送到LogServer上的fluentd,并根据规则存盘,简图如下:
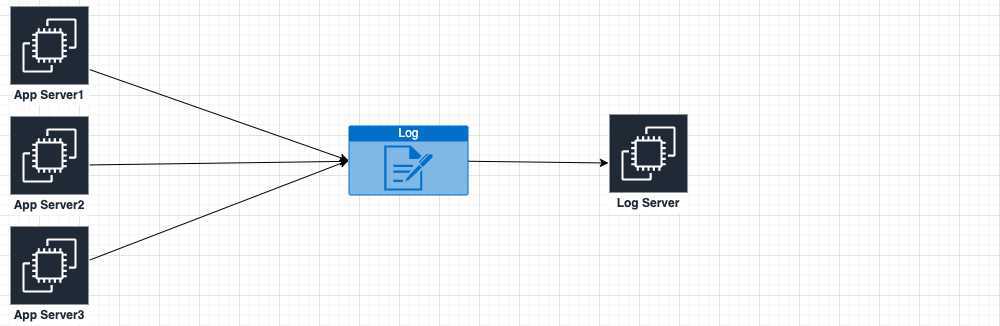
由于想把多台AppServer上的日志集中到一台机器,那么应用程序的日志输出位置应该是有规律的、固定的(和研发人员商定), 下面用我做过的一个具体需求举例分析:
日志目录结构:
├── public │ └── release-v0.2.20 │ └── sys_log.log ├── serv_arena │ └── release-v0.1.10 ├── serv_guild │ └── release-v0.1.10 │ └── sys_log.log ├── serv_name │ └── release-v0.1.10 │ └── sys_log.log
通过日志目录结构可以发现,服务器上运行了public、serv_arena等微服务,微服务目录里是程序版本,程序版本目录可能有多个,程序版本目录中是最终log。
日志原始格式:
这里输出的日志是纯文件格式,有些日志则可能是Json等其它格式,对于不同格式,可以选则不同的parser来处理
研发人员的需求是:
日志到LogServer后,目录结果不变。
下面是具体配置过程
step1:
在三台App Server上和LogServer上都安装Fluentd:
$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh
我当前的版本在安装完成后,会在/etc/td-agent/目录下生成td-agent.conf文件和plugin目录,我通常会再建立一个conf.d目录,并把所有配置文件细分放进去,并在td-agent.d里include进来,这是个人习惯,感觉很清爽。所以目录结构最后为:
# tree /etc/td-agent/
/etc/td-agent/
├── conf.d
├── plugin
└── td-agent.conf
step2:
Fluentd已经安装好了,下面就要对其进行配置,三台App Server上的配置是一样的,但是 LogServer上的配置略有不同,因为Fluentd在Logserver
端的角色是接收端。
LogServer端Fluentd配置:
# cat td-agent.conf <system> log_level info </system> <source> @type forward port 24224 bind 0.0.0.0 </source> @include /etc/td-agent/conf.d/*.conf
# cat conf.d/raid.conf <match raid.**> @type file path /mnt/logs/raid/%Y%m%d/${tag[4]}/${tag[5]}.${tag[6]}.${tag[7]}/${tag[8]}_%Y%m%d%H append true <buffer time, tag> @type file path /mnt/logs/raid/buffer/ timekey 1h chunk_limit_size 5MB flush_interval 5s flush_mode interval flush_thread_count 8 flush_at_shutdown true </buffer> </match>
这里值得一说的是path选项,这里用到了tag选项来获取一些信息,而tag信息是从AppServer端的Fluentd配置中传过来的,最后path的结果如下:
# tree /mnt/logs/ /mnt/logs/ └── raid ├── 20200623 │ ├── public │ └── serv_guild │ └── release-v0.1.10 │ └── sys_log_2020062307.log └── buffer
AppServer端Fluentd配置:
# cat td-agent.conf @include /etc/td-agent/conf.d/*.conf
<source> @type tail path /mnt/logs/raid/public/*/* pos_file /var/log/td-agent/public.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> refresh_interval 5s </source> <source> @type tail path /mnt/logs/raid/serv_arena/*/* pos_file /var/log/td-agent/serv_arena.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> </source> <source> @type tail path /mnt/logs/raid/serv_guild/*/* pos_file /var/log/td-agent/serv_guild.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> </source> <source> @type tail path /mnt/logs/raid/serv_name/*/* pos_file /var/log/td-agent/serv_name.log.pos tag raid.* <parse> @type none time_format %Y-%m-%dT%H:%M:%S.%L </parse> </source> <filter raid.**> @type record_transformer <record> host_param "#{Socket.gethostname}" </record> </filter> <match raid.**> @type forward <server> name raid-logserver host 10.83.36.106 port 24224 </server> <format> @type single_value message_key message add_newline true </format> </match>
这时值得一说的仍然是path和tag选项,我们配置的tag是raid.*,但实际tag的内容到低是什么呢?以致于tag传到LogServer后,我们能对tag进行一系列操作。
raid.*会匹配到path的路径,并把/用.代替,也就是tag raid.* 实际的内容类似:raid.mnt.logs.raid.public.release-v0.2.20.sys_log.log_2020062304.log
这样,我们后续根据tag进行目录配置才成为可能。
这里值得一说的还有format single_value参数, 如果不指定format为single_value,那你看到最终日志是如下这样,前面加了日期和tag, 这通常是我们不需要的,我们需要原样把日志打到LogServer上。message_key是fluentd自动给我们加上的,docker中的message key可能叫log add_newline相当于是否换行。

场景2:从LogServer把日志集中导入elasticSearch
通过场景一,日志已经可以集中到LogServer上,通过LogServer就可以进一步把日志导入es或其它的系统了。
原文:https://www.cnblogs.com/alexguome/p/13194353.html
评论(0)