关于对象序列化
前言
序列化是指将对象转换成可传输或可存储的形式的过程。常见的如文件存储,网络传输。
序列化是个过程,按照什么方式序列化呢?不同的序列化方式得到的结果也不近相同。微服务里超高的调用频率要求编解码的速度更快,大数据里要求数据存储的报文体积更小。
1. 序列化的定义 应用场景
如上面说到序列化用于将对象转换成可传输或存储的形式的过程。反序列化使用存储或传输内容重新创建对象的过程。
JSON/XML 序列化和 二进制序列化
网络传输中我们会序列化成JSON或XML,可读性好,通用。但直观和通用的同时也带来了性能差的缺点。信息冗余了很多,键值对方面,会有重复的key值。
而序列化成二进制流,然后在二进制流中规定相关协议。我们就可按照协议来恢复成目标对象。
2. 关于二进制序列化
2.1 优化原理
空间优化:
- 去掉字段描述,比如JSON 传递用户信息{"id":123,"text":"you"} 中需要将key值告诉client端。如果server端和client端规定好N长度的字节表式id 第二个N长度的字节表示text 内容直接是you,然后传递的内容就是123you client端依然知道我们在表达什么。
- 使用 varint 去压缩数值
时间优化:
- 避免多余的拷贝。由于tcp本身就是基于二进制传输。二进制序列化省去了把二进制转成字符串,再解析字符串的过程。直接基于Socket读取到的字节流还原即可!
- 不需要中间变量,减少了长字符串等大内存对象,大大节省了系统gc的时间。
- 基于位置偏移按顺序逐个还原字段,减少了解析json/dom结构的时间。
2.2 序列化评判指标
- 速度:序列化/反序列化需要的时间,越快越好
- 体积:数据包的长度。越小越好。
- 表达力:指的是支持对象的复杂度,比如Java 首先支持基本类型的转换,也要支持自定义的Java Bean 和复杂的嵌套对象,集合等。
- 自由度:有的序列化框架需要在服务方先生成一个描述文件(IDL)。然后发给消费侧使用。比如Protobuf,需要用他的命令行生成一个.proto文件,每个小版本生成的代码还不一样,相互不兼容。这样以后加字段,版本升级都很受限制。有的则完全不需要IDL,使用起来高度自由。
- 跨语言能力:很多互联网企业内部并没有做语言要求。比如服务是java的,调用方可能是php, c#。这就要求序列化方案支持主流语言,并且各语言的反序列化结果要保持基本一致。
以上有些指标之间是相互冲突的,实现的时候必须要在他们之间做出平衡。比如体积和表达力之间很显然是矛盾的。另外往往支持多语言的话,那么他在某一个语言上的自由度就要打折扣。比如Protobuf支持跨语言,就得使用IDL。但是他的纯java版本protostuff是完全不需要IDL的,使用起来特别灵活。
2.3 常见框架
- Protobuf:Protobuf是Google出品的序列化方案。Google出品,必属精品!Protobuf知名度很高,轻便高效稳定是它的特点。
- Thrift:Thrift最早由facebook开发,成熟后捐献给apache成为顶级项目。他实际上是一款rpc框架,其中的序列化部分也可以拿出来单独使用
- Hessian:Hessian是一个历史悠久的rpc框架。其中的序列化部分也可以拿出来单独使用。在java体系应用尤多。Hessian是Dubbo的默认序列化协议。
- Kyro:Kryo是一个小巧高效的 Java 序列化库,在hive,storm,spark等大数据领域使用的比较多。在算子函数的参数传输,Shuffle,RDD持久化等方面提效显著。缺点是多语言支持比较弱。
- Avro:Avro是apache出品的序列化框架。和hadoop项目是同一个作者。需要json格式的IDL文件。在数据包体积方面很有优势。
3. 实现原理
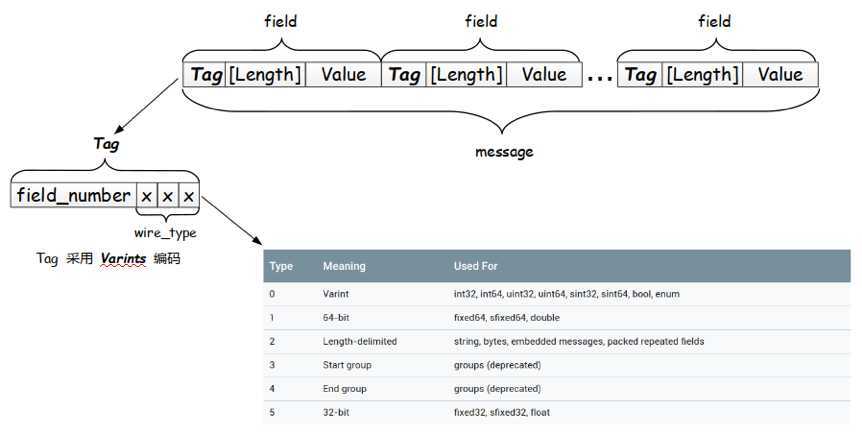
- 使用 TLV 进行编码
TLV本身是一个电信领域的编码标准。TLV指的是由数据的类型Tag,数据的长度Length,数据的值Value组成的三元组结构体,几乎可以描任意数据类型,TLV还可以继续嵌套,Value也可以是一个TLV结构,基于这种嵌套的特性,可以让我们用来表达复杂对象。
Protobuf 就使用了 TLV 的结构,结构如下图
2. varint 算法
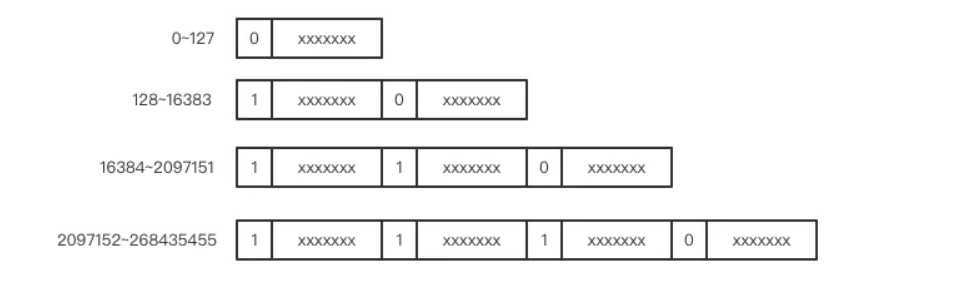
varint算法是一种变长的数值编码算法(variable integer)。我们都知道,在语言规范中,int总是固定为4个字节长度。取值范围为-231——231-1,即-2147483648——2147483647。但根据统计发现,程序中使用到的大部分int都不需要这么长。varint算法正是利用到了这一点来做优化。
数值非常小时,只需要使用一个字节来存储,数值稍微大一点可以使用 2 个字节,再大一点就是 3 个字节,它还可以超过 4 个字节用来表达长整形数字。
其原理也很简单,就是保留每个字节的最高位的 bit 来标识是否后面还有字节,1 表示还有字节需要继续读,0 表示到读到当前字节就结束。
- 局部再调优
对于某些局部细节还可以继续做优化。
- 对于repeated消息的优化。对于数组,List这种会在一段数据内连续出现同一种类型的对象。那么TLV 中的 Tag可以做合并。比如对于连续多个varint的表达可以从TVTVTV变成TVVV。对于连续多个字符串的表达可以从TLVTLVTLV变成TLVLVLV
- 默认值不参与编码,比如boolean默认false,可以从TLV结构变成T,消费侧不消耗任何字节直接赋值为false即可!
- 关于varint上图是一种最直观的实现,实际工程里可以通过补码再反转等一些手段提高处理速度。
对于负数,可以通过ZigZag 编码映射到正数处理。
zigzag 编码将整数范围一一映射到自然数范围,然后再进行 varint 编码。
0 => 0
-1 => 1
1 => 2
-2 => 3
2 => 4
-3 => 5
3 => 6
zigzag 将负数编码成正奇数,正数编码成偶数。解码的时候遇到偶数直接除 2 就是原值,遇到奇数就加 1 除 2 再取负就是原值。
4. 序列化的坑
-
序列化方案一定要反复论证,在空间使用上最好留有一定的余地。而且服务调用的时候协议要由消费侧主动传递。否则一旦大规模的使用之后,几乎无法升级。
-
要由框架来规定字段的顺序,保证新添加的字段在尾部。假如使用java反射这样的机制获取字段顺序。新添加的字段TLV结构体可能会跑到字节流中间。消费侧无法做丢弃。
-
对于比较长的对象数据(长度超过一个字节的表达能力)曾尝试过用magic byte来作为结束标志(类似Hession的 x7a)。这样就可以替代Length。结果发现破坏了TLV结构带来的成本要远大于提升的性能开销,而且理论上有碰撞的风险。
-
循环引用是一个需要注意的问题。可以借鉴fastjson等工具的处理方法,在整个链条上引入一个map来保存之前处理过的对象。然后把引用类型定义为一种特殊的wire_type,消费侧处理到相应的字节直接去map里拿。这个场景要注意一个特殊情况,带泛型的EmptyList。
-
基于get/set方法还是类的属性来做序列化?个人建议基于属性。不同于java语言规范,序列化结果可能在非标准的场景下去使用。基于get/set方法会带来很大的复杂度。
-
对于继承的处理需要注意一些特殊情况,父子类是可以出现同名字段的。
-
对语言规范要理解的全面深刻,比如枚举对象是new不出来的, final属性类似。
-
微服务传输用的数据结构,本身就应该是标准的,简洁的。所以没必要把框架定位成江湖百晓生。对于一些小众的数据结构,比如CollectionUtils.synchronizedCollection不支持并不丢人。
References
原文:https://www.cnblogs.com/wei57960/p/13155094.html