数据库常用的索引结构
数据库常用的索引结构
一个最简单的数据库:
#!/bin/bash
db_set() {
echo "$1, $2" >> database
}
db_get(){
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
底层存储格式:一个名叫database的纯文本文件。每一行都是一个键值对,每次调用db_set就在文本最后添加新内容,相同键值的旧内容不会被覆盖。db_get查找文件中最后一次出现的键值来找到最新值。
数据库使用的日志也是一个仅支持追加式更新的数据文件。如果使用上述最简单的数据库来保存日志,当日志中保存大量内容时,db_get函数的性能会很差,它是O(n)的。
为了高效查找数据库中特定的键值,需要引入索引。
哈希索引
假设数据存储全部采用追加式文件,那么利用哈希索引来解决上述问题就可以采取如下策略:内存中的HashMap把每个键值一一映射到数据文件中特定的字节偏移量。
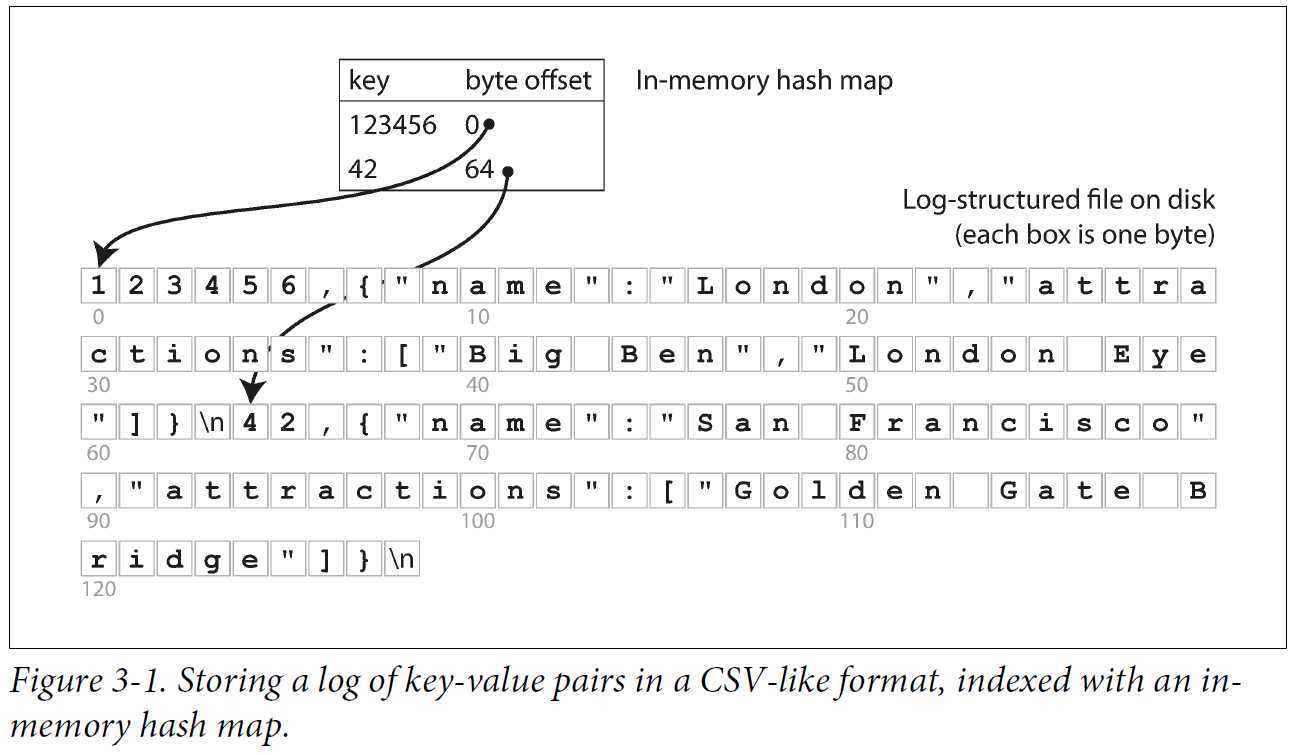
在这种策略下,为了获取某个值,只需要一次磁盘寻址就可以将value加载进内存。这种策略非常适合每个键的值频繁更新的场景。
由于我们采用的是追加式的更新,当数据非常多时可能会面临磁盘用尽的情况。解决方案:将日志文件(database文件)分解成固定大小的段,当文件达到一定程度大小时就关闭,并将后续写入到新的段文件中。同时,可以在关闭的文件中进行压缩,消除重复的键,只保留最新的键值对。对于这些段的更新可以交给后台线程完成。

当对日志段进行压缩以后,其大小往往会小于符定段大小,那么还可以对多个被压缩过的日志段进行合并。这个合并过程也可以交给后台线程完成,在这期间被冻结的旧日志段依然可以读写。当合并完成后,后续的读写可以切换到新的合并段上。
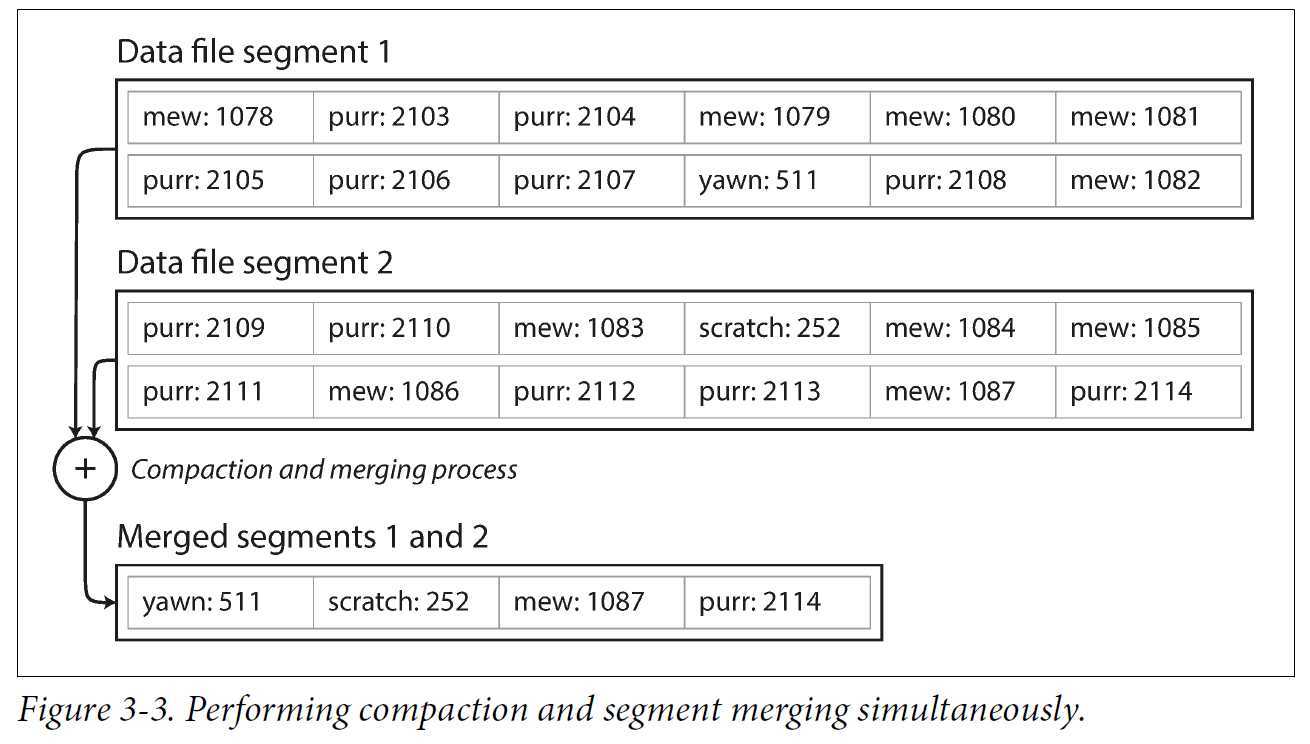
在实际使用中,还需要考虑很多其他问题,才能真正使该策略行之有效:
- 文件格式:日志文件采取何种格式
- 记录删除:由于采取追加式更新,需要在日志文件中追加一个特殊的删除标记(墓碑记录)
- 崩溃恢复:数据库重启,内存中的hashmap丢失,可以采取从尾到头读取所有段文件方式,或者将hashmap的快照保存在磁盘上
- 部分写入的数据:需要校验码
- 并发控制:由于写操作是顺序的,所以可以只用一个写线程。可以允许多个线程同时读
追加式日志的好处:
- 追加和合并操作是顺序写,性能比随机写高得多。
- 段文件是追加式的,那么并发和崩溃恢复要更简单
- 旧段的合并可以避免碎片化
局限性:
- 哈希表必须全部放入内存。如果有大量的键,导致需要磁盘介入时,性能大幅降低。哈希表需要大量随机IO访问,哈希表变满时,继续增长代价昂贵,并且哈希冲突时需要复杂处理逻辑。
- 区间查询效率不高。查询区间时,只能采取逐个查找的方式查询每一个键值。
SSTables和LSM-Tree
在哈希索引结构中,日志文件中的每个存储段都是一个键值对序列,键值对按照写入顺序排序,后出现的键值优于之前的值。
SSTable(Sorted String Table):排序字符串表。将段文件中的键值对按键排序,并且要求每个键在合并的段文件中只能出现一次(段文件压缩过程已经确保了)。
相比哈希索引的优势:
- SSTable索引的日志文件,依然需要进行日志段的合并。但是由于每个段内都是按键排序的,那么合并过程可以并发读取多个段,按照MergeSort中的Merge过程,进行合并。合并操作的代价相比哈希索引日志段更小。

- 在日志中查找特定键时,不需要在内存中保存所有键的索引。内存中只需要保存稀疏索引,由于日志中按键排序,就算不知道具体段和偏移,也可以先根据内存中的稀疏索引,找到距离最近的键,再从该位置开始遍历查找。
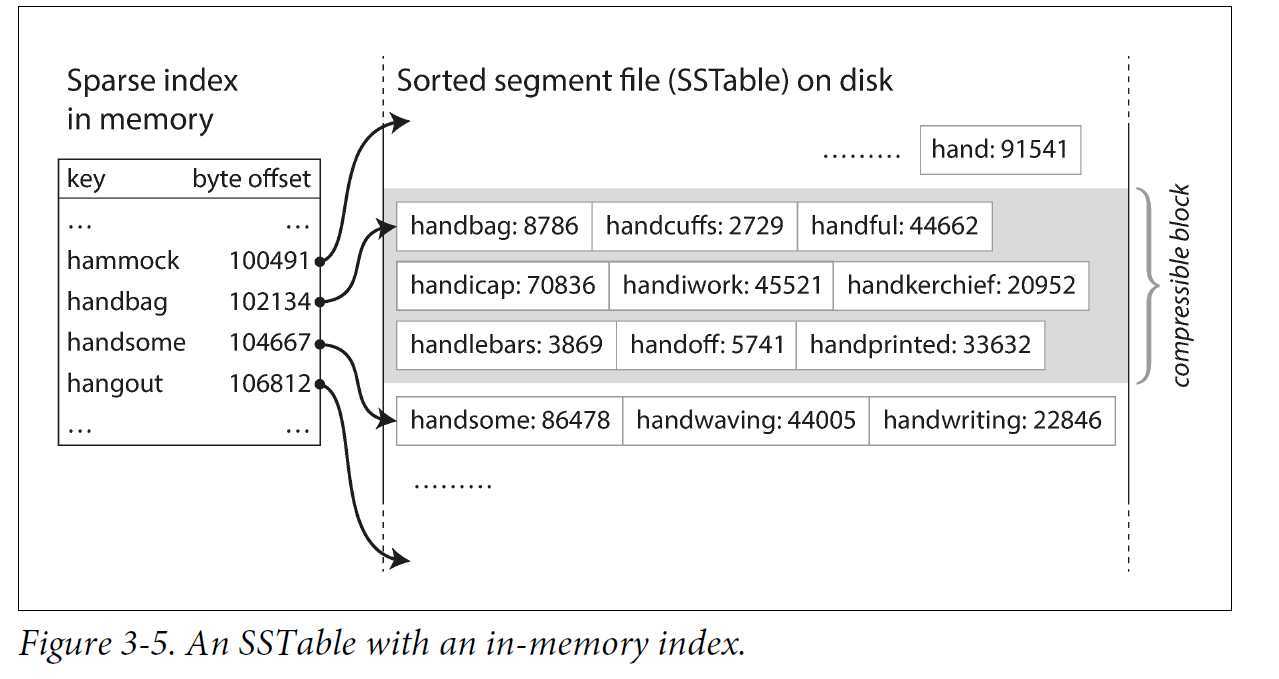
- 对于区间查询:由于日志段内数据有序,查询时一次读取一个日志段,就可以将之后所有需要查询的数据加载进内存。区间查询时效率更高,减少IO次数。
构建和维护SSTable
由于写入的键值会以任意顺序出现,需要解决如何将记录排序的问题。
基于磁盘的排序:B-trees
基于内存的排序:红黑树或AVL树
基于内存的红黑树或者AVL树的存储引擎工作流程:
- 写入时,将数据加入到内存中的平衡树数据结构中(内存表)
- 当内存表超过阈值大小时,将它写入磁盘。由于内存表中数据有序,那么写入磁盘后的记录就可以有序。新的SSTable文件成为数据库的最新部分。在写入磁盘的同时,新数据写入内存中的新的内存表实例
- 读操作:首先检查内存表,再查找磁盘上的最新段文件,接下来是次新,直到找到目标
- 后台进程周期性地执行段合并与压缩过程。
为了防止数据库崩溃导致数据出错,还需要在磁盘上保留单独的日志文件。日志文件以记录当前内存表中的操作记录,当内存表被写入磁盘后,日志就可删除。
从SSTable到LSM-Tree
LSM-Tree(Log-Structured Merge Tree)
基于日志和压缩排序文件原理的存储引擎都被称为LSM存储引擎。
性能优化
在LSM-Tree中查找一个不存在的键会很慢:首先搜索内存表,然后回溯所有段文件。优化:布隆过滤器
还有对SSTable压缩和合并具体顺序与时机的优化。
B-trees
是几乎所有关系数据库中的标准索引实现。
B-tree将数据库分解成固定大小的块或页,传统上大小为4KB,页是内部读/写的最小单元。每个页面都可以使用地址或位置进行标识,页面之间依此标识进行相互引用。
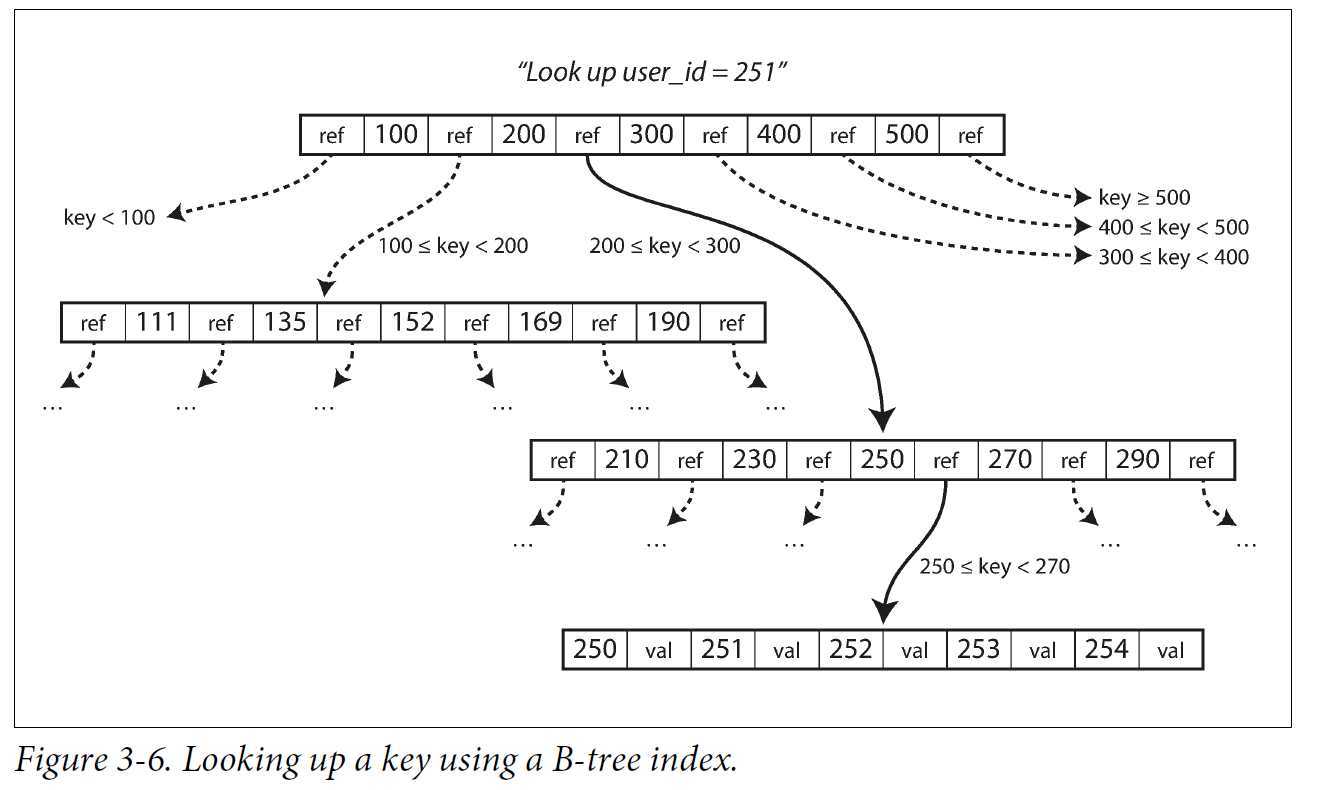
某个页面被指定为B-tree的根,所有查询都是从根页面开始的。
B-tree中一个页所包含的子页引用数量成为分支因子。上图中的分支因子为6。
添加新键时,首先找到范围包含该键的页,并将其添加到页面中,如果页面空间不足以容纳新键,则需要将页面分裂为两个半满的页,其父页面需要更新,以包含新分裂的页。
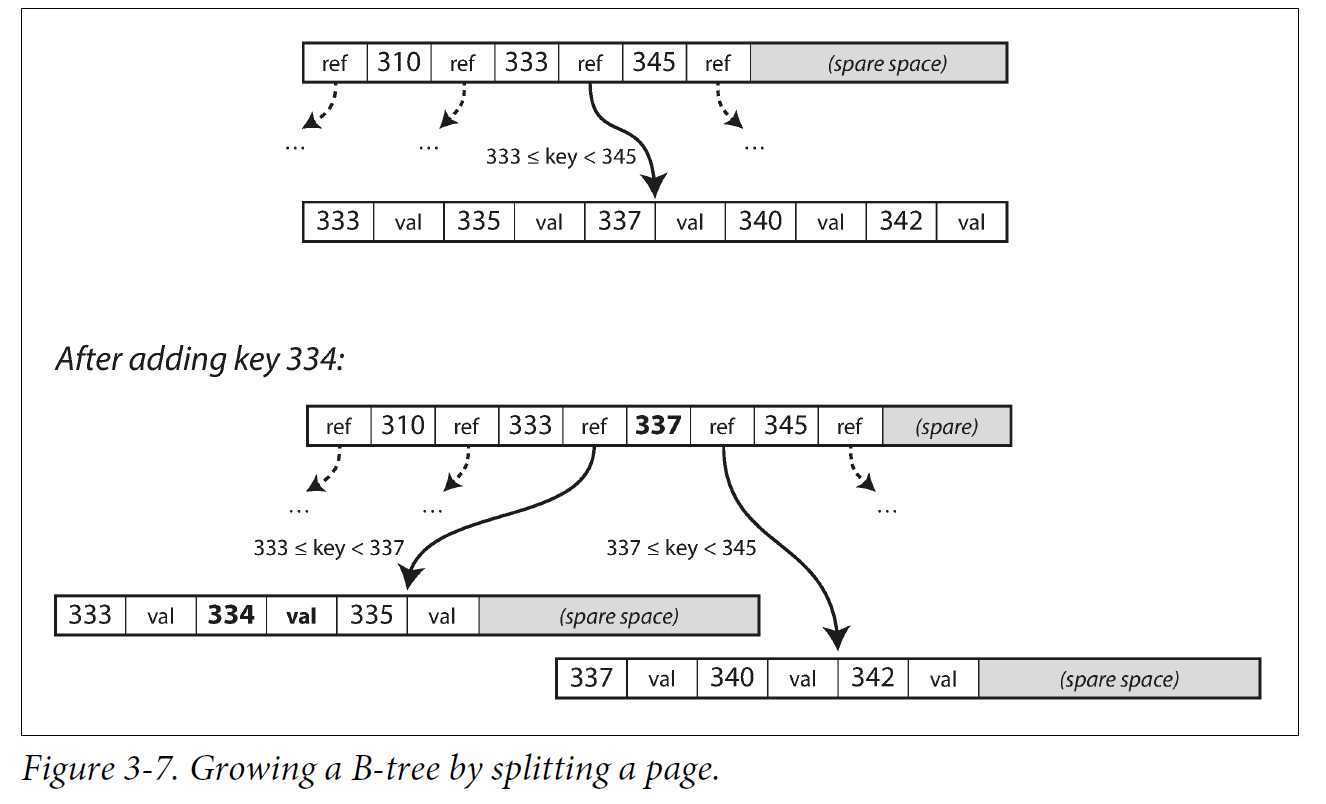
B-tree总是保持平衡的:具有 n 个键的B-tree总是具有O(log n)的深度。
B-tree的基本写操作是使用新数据覆盖磁盘上的旧页。
关于使用B-tree的可靠性:
有些操作需要覆盖多个不同的页,例如,插入操作导致页溢出。这种操作往往比较危险,因为如果数据库在完成部分页写入之后发生崩溃,会导致索引结构破坏。
为了解决数据库崩溃之后数据恢复问题,可以采用预写日志(write-head log WAL)。预写日志是一个仅支持追加修改的文件,每个B-tree的修改必须先更新WAL再修改树本身的页。
优化B-tree
- 一些数据库不采用WAL来进行崩溃恢复,而是使用写时复制技术。
- 保留键的缩略信息,而不是完整的键,节省页空间。
- 尝试把相邻页放在磁盘中的相邻的块上,优化区间查询效率。
- 增加额外的指针指向相邻页
对比LSM-Tree与B-Tree
根据经验,LSM-Tree写入更快,B-Tree查询更快。
LSM-Tree的优点
B-tree索引必须写入两次数据,一次写入预写日志,另一次写入树的页本身。
LSM-tree索引时,由于反复压缩和SSTabel的合并,日志结构索引也会导致重写数据多次。
在数据库内,一次数据写入请求导致的多次磁盘写被称为写放大。
LSM-tree由于以顺序方式写入紧凑的SSTable,而不必重写树中的多个页,所以LSM-tree具有较低的写放大。所以LSM-tree通常能够承受比B-tree更高的写入吞吐量。
LSM-tree可以支持更好的压缩,因此磁盘上的文件比B-tree小很多。B-tree是基于页的,当页被分裂或者当一行内容不能适合现有页时,页中的空间无法使用。LSM-tree可以定期重写SSTable以消除碎片化。
LSM-Tree的缺点
由于LSM-tree的写入吞吐量很高,而磁盘的写入带宽是有限的。磁盘的写入带宽需要在初始写入(记录刷新内存表到磁盘)和后台运行的压缩线程之间共享。
当压缩没有被很好的配置时,就会发生压缩无法匹配新数据写入的情况。即,初始写入数据量太大,而压缩速率太小导致磁盘上未合并的段数量不断增加,导致磁盘空间不足。
原文:https://www.cnblogs.com/hezhiqiangTS/p/12796897.html