Deep Learning 最优化方法之AdaGrad
时间:2020-04-02 12:18:25
收藏:0
阅读:47
结论:
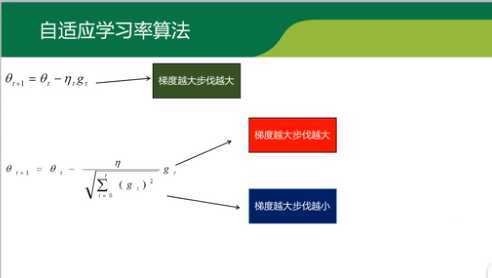
1.简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同
2.效果是:在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小)
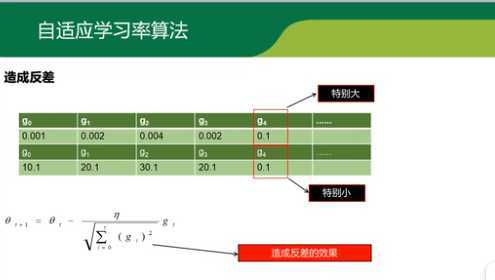
3.缺点是,使得学习率过早,过量的减少
4.在某些模型上效果不错。
算法流程如下:
具体推导流程如下:


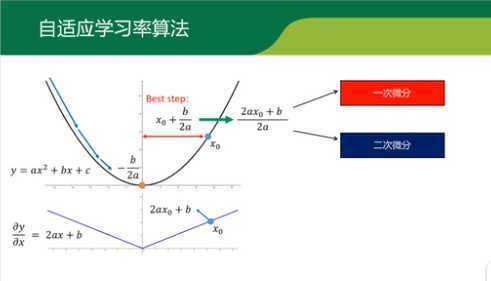
可看出从x0点到最优点-b/2a需要走的步长为x0+b /2a刚好是一次微分和二次微分的比值。
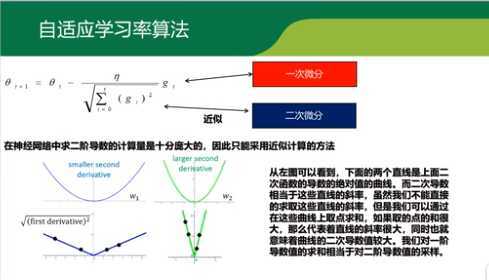

通过一阶导数近似斜率的方式,寻找其他代替减少大小就可以。
原文:https://www.cnblogs.com/limingqi/p/12618661.html
评论(0)