PostgreSQL内核学习笔记四(SQL引擎)
PostgreSQL实现了SQL Standard2011的大部分内容,SQL处理是数据库中非常复杂的一部分内容。
本文简要介绍了SQL处理的相关内容。
简要介绍
SQL文的处理分为以下几个部分:
- Parser阶段(词法分析,语法解析)
对应于source中的parser模块 - analyzer阶段(语义分析)
对应于source中的analyzer模块
内部处理中将Parser阶段生成的Parser tree转换为Query tree - rewriter阶段(查询重写)
安装规则系统进行查询重写,还有视图重新
对应于source中的rewriter模块 - Planner阶段(生成最优查询计划)
对应于source中planner模块 - Executor阶段(查询计划执行)
对应于source中executor模块
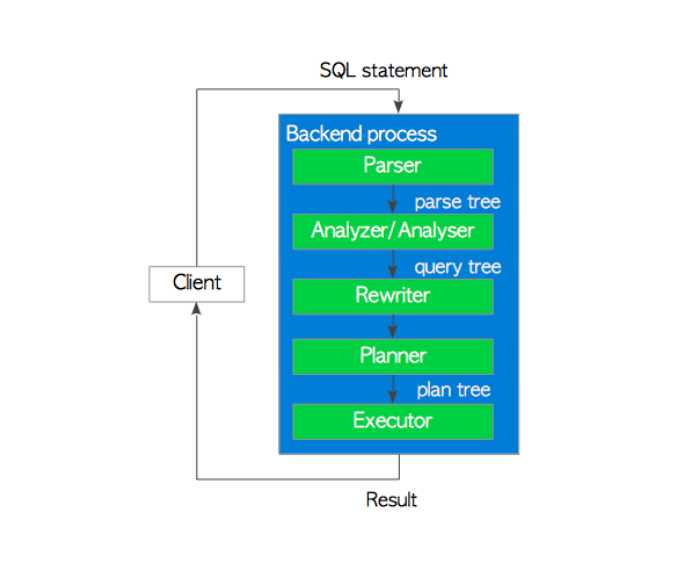
上图显示了SQL文处理的5个阶段。
Parser阶段
利用flex,bison等工具进行语法和语义分析,最终生成Parser tree。
输入:SQL文
输出:Parser tree
以下图为例,介绍下parser tree长什么样子
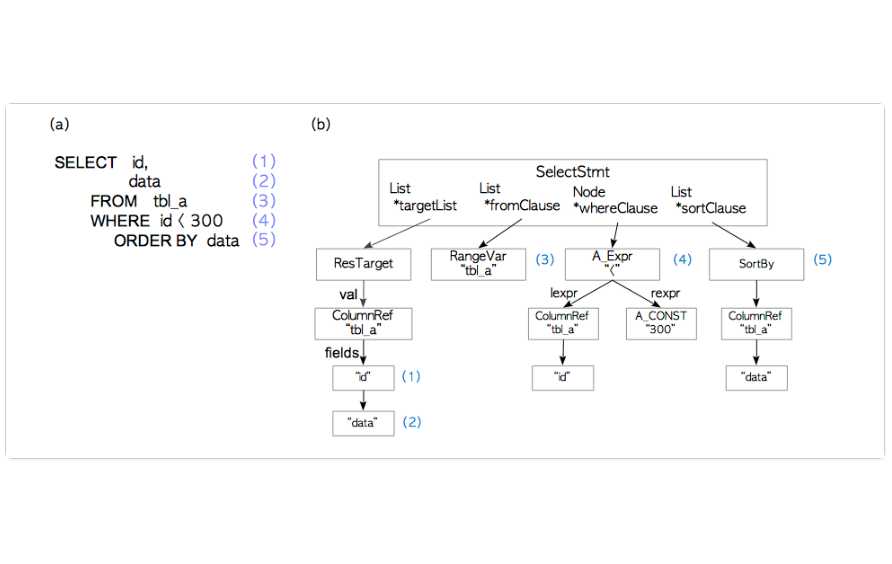
根据上图可以清晰的看到select的列对应于parser tree的target list
select 文的from部分对应于parser tree的from clause
select 文的where部分对应于parser tree的where clause
select文的order by部分对应于parser tree的sort clause
analyzer阶段
对于parser阶段的生成parser tree进行语义分析,生成Query tree
输入:Parser tree
输出:Query tree
以下图为例,介绍下Query tree长什么样子
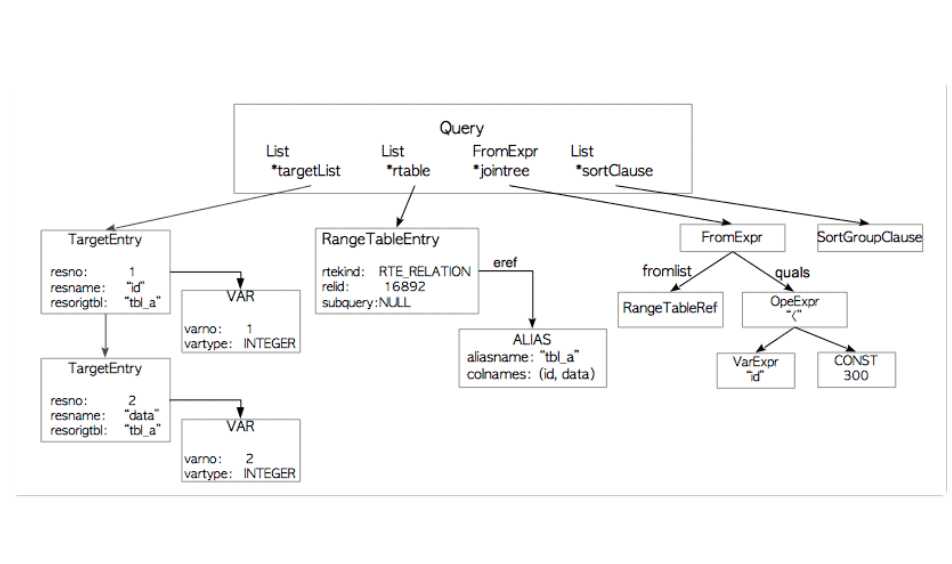
targetlist 是select文的查询结果的list。以上图为例select文查询的列有两个id和data,则targetlist有两个元素,每个元素对应于一个TargetEntry。
rtable表示范围表range table,是所有表的list。
jointree 存储了from clause和where clause。
rewriter阶段
根据pg_rule系统catalog中的规则将改变Query tree。
输入:Query tree
输出:Query tree
以视图为例
sampledb=# CREATE VIEW employees_list
sampledb-# AS SELECT e.id, e.name, d.name AS department
sampledb-# FROM employees AS e, departments AS d WHERE e.department_id = d.id;sampledb=# SELECT * FROM employees_list根据上图所示,Querytree中范围表rtable中的内容进行了转变。
Planner
根据rewriter阶段的Query tree生成最优查询计划树Plan tree,然后通过执行器executor进行执行。
PostgreSQL中Plan tree可以通过EXPLAIN命令进行显示
testdb=# EXPLAIN SELECT * FROM tbl_a WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_a (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
(4 rows)下图显示了Plan tree和EXPLAIN执行结果的关系
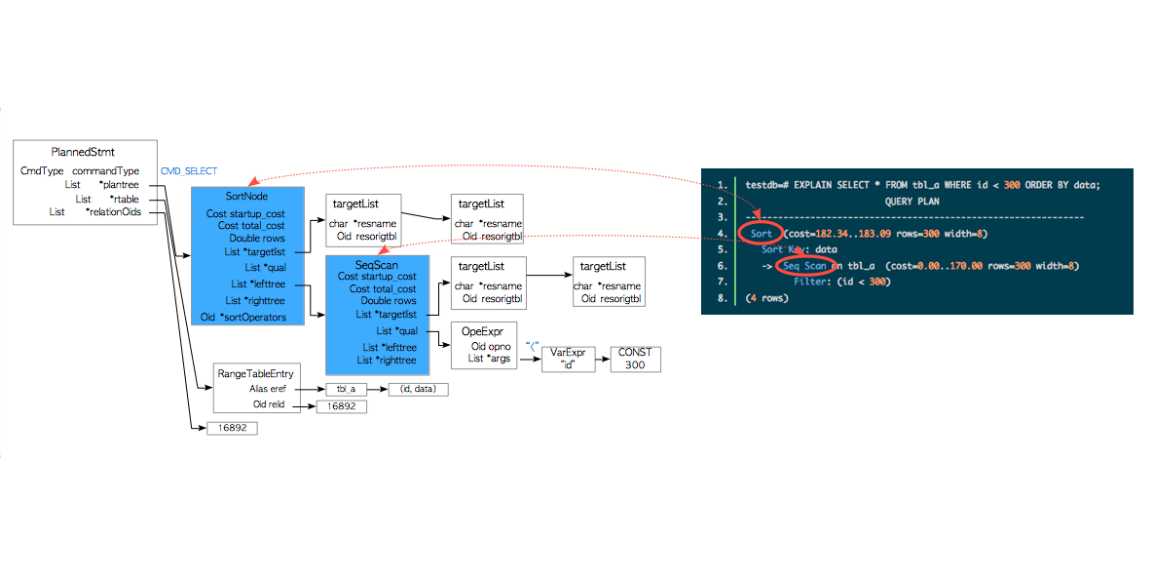
plan tree的类型有很多种,上图中是SortNode类型,source文件 plannodes.h中定义了所有的类型。
执行器在执行时先从Plan tree的底部开始执行,最后到顶部。
以上图为例,先对table_a进行顺序扫描,然后再进行排序获得最终结果。
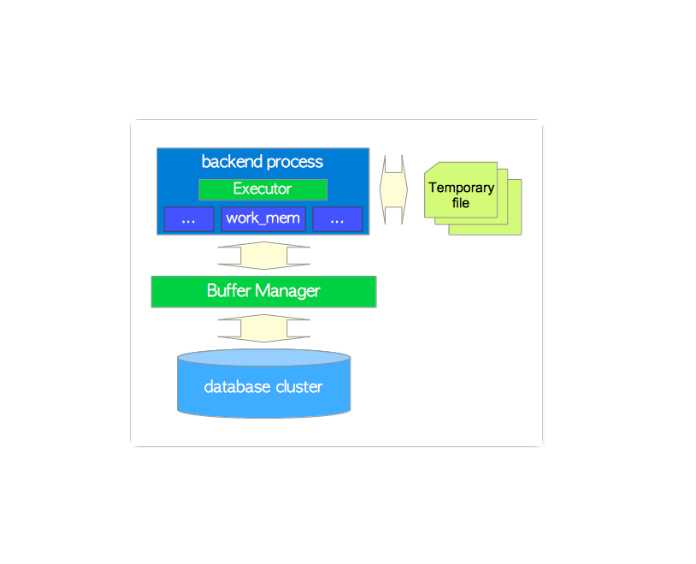
Executor
执行器执行plan tree的过程中,通过buffer manager进行table和index的读写。执行时也需要一些内存比如:temp_buffers, work_mem,包括一些临时文件。
此外在存取元组时,PostgreSQL会用到mvcc机制保证并发时事务的一致性和隔离性
参考文档:
http://www.interdb.jp/pg/pgsql03.html#_3.ref.1
原文:https://www.cnblogs.com/haylee/p/12272475.html