打开网站URL遇到“HTTP Error 418:”问题
时间:2020-02-05 17:04:20
收藏:0
阅读:426
问题:urllib.error.HTTPError: HTTP Error 418:
程序:
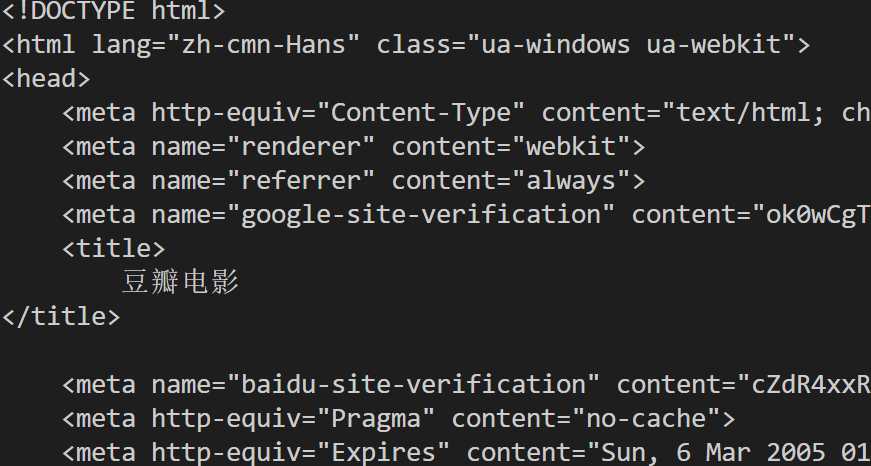
import urllib.request response=urllib.request.urlopen(‘https://movie.douban.com/‘) html=response.read().decode(‘utf8‘) print(html)
运行程序读取网页时显示:

“HTTP Error 418:”应该是网站的反爬程序返回的。
在使用浏览器访问网站时,访问请求中包含请求头。检测请求头是常见的反爬虫策略。
服务器通过检测请求头判断这次请求是不是人为的。
在程序上加入请求头,这样服务器就会认为这是一个从浏览器发出的人为请求:
import urllib.request url=‘https://movie.douban.com/‘ #请求头 herders={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.36 (KHTML,like GeCKO) Chrome/45.0.2454.85 Safari/537.36 115Broswer/6.0.3‘, ‘Referer‘:‘https://movie.douban.com/‘, ‘Connection‘:‘keep-alive‘} req=urllib.request.Request(url,headers=herders) response=urllib.request.urlopen(req) html=response.read().decode(‘utf8‘) print(html)
返回正确结果。
原文:https://www.cnblogs.com/winterbear/p/12263886.html
评论(0)