pandas读取文件的read_csv()方法
时间:2020-02-02 10:15:39
收藏:0
阅读:827
import pandas as pd
pd.read_csv(filepath_or_buffer,header,parse_dates,index_col)
返回数据类型:
DataFrame:二维标记数据结构
列可以是不同的数据类型,是最常用的pandas对象,如同Series对象一样接受多种输入:lists/dicts/Series/DataFrame
参数:
filepath_or_buffer:
字符串,或者任何对象的read()方法。这个字符串可以是URL,有效的URL方案包括http、ftp、s3和文件。可以直接写入"文件名.csv"
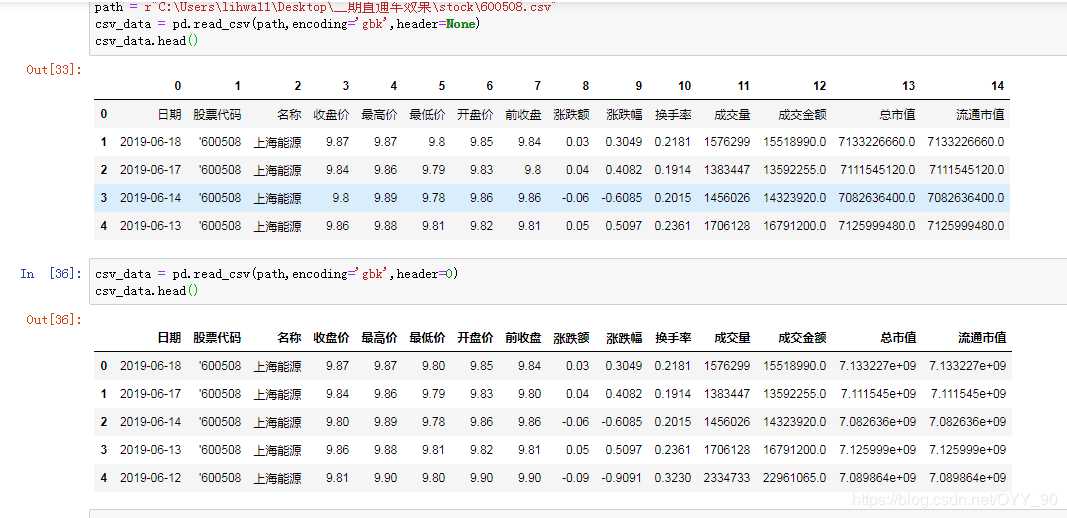
header:
将行号用作列名,且是数据的开头。
注意当skip_blank_lines=True时,这个参数忽略注释行和空行。所以header=0表示第一行是数据而不是文件的第一行。
(1)、header=None
即指定原始文件数据没有列索引,这样read_csv为其自动加上列索引{从0开始}
ceshi.csv原文件内容:
c1,c2,c3,c4
a,0,5,10
b,1,6,11
c,2,7,12
d,3,8,13
e,4,9,14
df=pd.read_csv("ceshi.csv",header=None)
print(df)
结果:
0 1 2 3
0 c1 c2 c3 c4
1 a 0 5 10
2 b 1 6 11
3 c 2 7 12
4 d 3 8 13
5 e 4 9 14
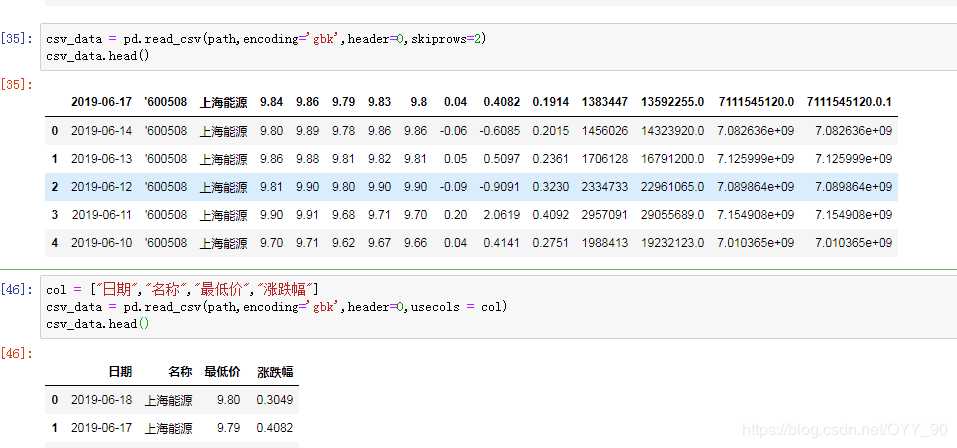
(2)、header=None,并指定新的索引的名字names=seq序列
df=pd.read_csv("ceshi.csv",header=None,names=range(2,6))
print(df)
结果:
2 3 4 5
0 c1 c2 c3 c4
1 a 0 5 10
2 b 1 6 11
3 c 2 7 12
4 d 3 8 13
5 e 4 9 14
(3)、header=0
表示文件第0行(即第一行,索引从0开始)为列索引
df=pd.read_csv("ceshi.csv",header=0)
print(df)
结果:
c1 c2 c3 c4
0 a 0 5 10
1 b 1 6 11
2 c 2 7 12
3 d 3 8 13
4 e 4 9 14
(4)、header=0,并指定新的索引的名字names=seq序列
df=pd.read_csv("ceshi.csv",header=0,names=range(2,6))
print(df)
结果:
2 3 4 5
0 a 0 5 10
1 b 1 6 11
2 c 2 7 12
3 d 3 8 13
4 e 4 9 14
注:这里是把原csv文件的第一行换成了range(2,6)并将此作为列索引
参考:
https://www.jianshu.com/p/ebb64a159104
https://www.cnblogs.com/guolongnv/articles/9965650.html
https://blog.csdn.net/OYY_90/article/details/92814266
原文:https://www.cnblogs.com/ratels/p/12250931.html
评论(0)