lucene&solr全文检索_4改进
时间:2020-02-01 21:02:54
收藏:0
阅读:89
在之前的程序中我们发现分词不太准确,因此我们可以使用支持中文分词。
分析器的执行过程:
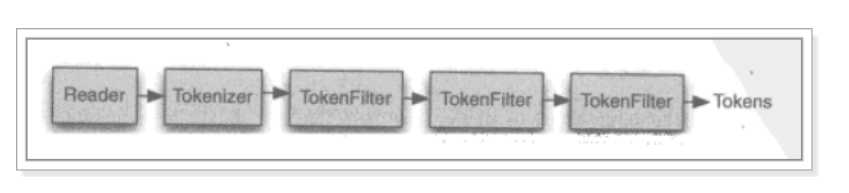
从一个reader字符流开始,创建一个基于reader的tokenizer分词器,经过三个tokenfilter(第一个大写变小写,第二个用回车替换空格,去掉不需要的a,the,and,逗号等)生成tokens。要看分析器的分析效果只需要看tokenstream中的内容就可以了,每个分析器都有一个方法tokenstream,返回一个tokenstream对象。
lucene自带中文分析器:
standardAnalyzer:单字分词即一个一个分
CJKAnalyzer:二分法,即两个一分,、
SmartChineseAnalyzer:对中文支持好,但扩展性差,对词库的操作不是很好处理。
由此可见上面三个分析器效果并不是很理想,因此要使用第三方分析器:
- paoding: 庖丁解牛最新版在 https://code.google.com/p/paoding/ 中最多支持Lucene 3.0,且最新提交的代码在 2008-06-03,在svn中最新也是2010年提交,已经过时。
- mmseg4j:最新版已从 https://code.google.com/p/mmseg4j/ 移至 https://github.com/chenlb/mmseg4j-solr,支持Lucene 4.10,且在github中最新提交代码是2014年6月,从09年~14年一共有:18个版本,也就是一年几乎有3个大小版本,有较大的活跃度,用了mmseg算法。
- IK-analyzer: 最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene 4.10从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 但是也就是2012年12月后没有在更新。
- ansj_seg:最新版本在 https://github.com/NLPchina/ansj_seg tags仅有1.1版本,从2012年到2014年更新了大小6次,但是作者本人在2014年10月10日说明:“可能我以后没有精力来维护ansj_seg了”,现在由”nlp_china”管理。2014年11月有更新。并未说明是否支持Lucene,是一个由CRF(条件随机场)算法所做的分词算法。
- imdict-chinese-analyzer:最新版在 https://code.google.com/p/imdict-chinese-analyzer/ , 最新更新也在2009年5月,下载源码,不支持Lucene 4.10 。是利用HMM(隐马尔科夫链)算法。
- Jcseg:最新版本在git.oschina.net/lionsoul/jcseg,支持Lucene 4.10,作者有较高的活跃度。利用mmseg算法。
我们使用IKanalyzer,需要导入jar包: ,并将核心文件放入src中
,并将核心文件放入src中 ,然后就可以使用了。
,然后就可以使用了。
同时你可以在xml文件中扩展
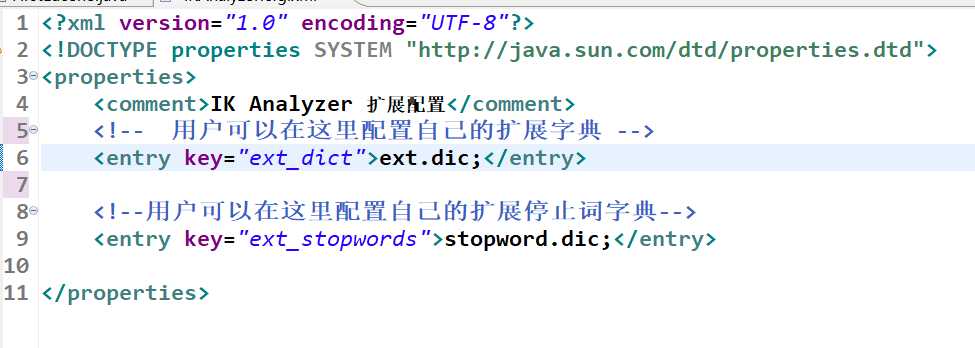
扩展的内容在ext.dic中(可以复制stopword.dic然后删除内容,重新输入自己想要扩展的内容)例如在ext.dic中加入高富帅白富美等
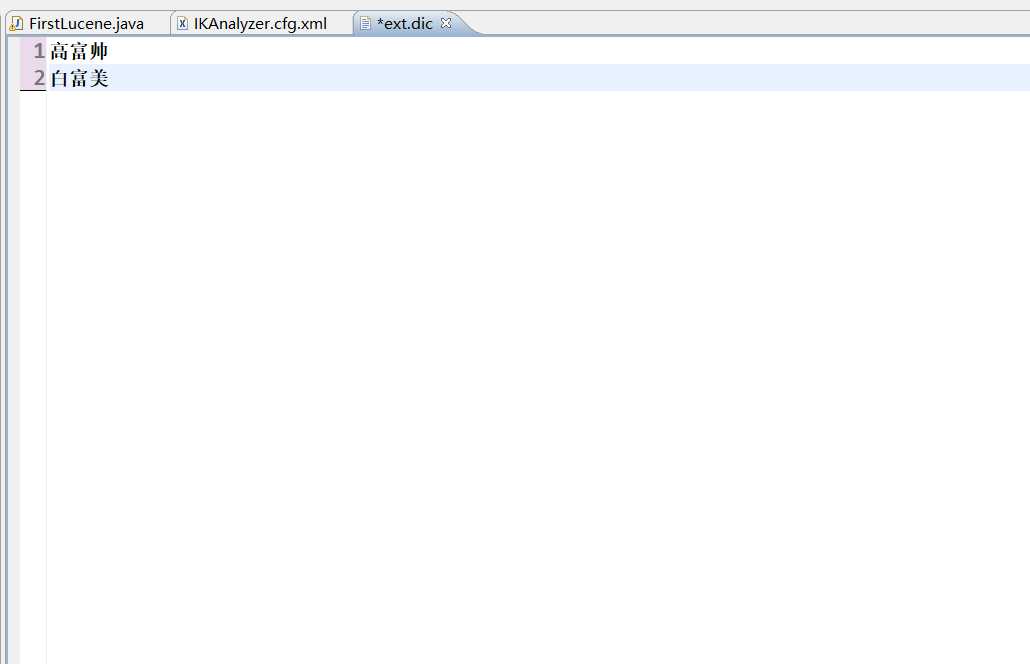
打开stopword.dic,即分析之后删除的文字。

注意无论使用什么分析器,都要注意搜索使用的分析器要和索引使用的分析器一致。
原文:https://www.cnblogs.com/tkg1314/p/12249934.html
评论(0)