Dubbo学习笔记8:Dubbo的集群容错与负载均衡策略
Dubbo的集群容错策略
正常情况下,当我们进行系统设计时候,不仅要考虑正常逻辑下代码该如何走,还要考虑异常情况下代码逻辑应该怎么走。当服务消费方调用服务提供方的服务出现错误时候,Dubbo提供了多种容错方案,缺省模式为failover,也就是失败重试。
Dubbo提供的集群容错模式
下面看下Dubbo提供的集群容错模式:
Failover Cluster:失败重试
当服务消费方调用服务提供者失败后自动切换到其他服务提供者服务器进行重试。这通常用于读操作或者具有幂等的写操作,需要注意的是重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。
接口级别配置重试次数方法 <dubbo:reference retries="2" /> ,如上配置当服务消费方调用服务失败后,会再重试两次,也就是说最多会做三次调用,这里的配置对该接口的所有方法生效。当然你也可以针对某个方法配置重试次数如下:
<dubbo:reference>
<dubbo:method name="sayHello" retries="2" />
</dubbo:reference>
Failfast Cluster:快速失败
当服务消费方调用服务提供者失败后,立即报错,也就是只调用一次。通常这种模式用于非幂等性的写操作。
Failsafe Cluster:失败安全
当服务消费者调用服务出现异常时,直接忽略异常。这种模式通常用于写入审计日志等操作。
Failback Cluster:失败自动恢复
当服务消费端用服务出现异常后,在后台记录失败的请求,并按照一定的策略后期再进行重试。这种模式通常用于消息通知操作。
Forking Cluster:并行调用
当消费方调用一个接口方法后,Dubbo Client会并行调用多个服务提供者的服务,只要一个成功即返回。这种模式通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
Broadcast Cluster:广播调用
当消费者调用一个接口方法后,Dubbo Client会逐个调用所有服务提供者,任意一台调用异常则这次调用就标志失败。这种模式通常用于通知所有提供者更新缓存或日志等本地资源信息。
如上,Dubbo本身提供了丰富的集群容错模式,但是如果您有定制化需求,可以根据Dubbo提供的扩展接口Cluster进行定制。在后面的消费方启动流程章节会讲解何时/如何使用的集群容错。
失败重试策略实现分析
Dubbo中具体实现失败重试的是FailoverClusterInvoker类,这里我们看下具体实现,主要看下doInvoke代码:

public Result doInvoke(Invocation invocation,final List<Invoker<T>> invokers,LoadBalance loadbalance) throws RpcException{
// (1) 所有服务提供者
List<Invoker<T>> copyinvokers = invokers;
checkInvokers(copyinvokers,invocation);
// (2)获取重试次数
int len = getUrl().getMethodParameter(invocation.getMethodName(),Constants.RETRIES_KEY,Constants.DEFAULT_RETRIES) + 1;
if(len <= 0){
len = 1;
}
// (3)使用循环,失败重试
RpcException le = null; // last exception
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyinvokers.size());
Set<String> providers = new HashSet<String>();
for(int i=0;i<len;i++){
// 重试时,进行重新选择,避免重试时invoker列表已发生变化
// 注意:如果列表发生了变化,那么invoked判断会失效,因为invoker示例已经改变
if(i > 0){
// (3.1)
checkWhetherDestroyed(); // 如果当前实例已经被销毁,则抛出异常
// (3.2) 重新获取所有服务提供者
copyinvokers = list(invocation);
// (3.3) 重新检查一下
checkInvokers(copyinvokers,invocation);
}
// (3.4) 选择负载均衡策略
Invoker<T> invoker = select(loadbalance,invocation,copyinvokers,invoked);
invoked.add(invoker);
RpcContext.getContext().setInvokers((List)invoked);
// (3.5) 具体发起远程调用
try{
Result result = invoker.invoke(invocation);
if(le != null && logger.isWarnEnabled()){
...
}
return result;
}catch(RpcException e){
if(e.isBiz()){ // biz exception
throw e;
}
le = e;
}catch(Throwable e){
le = new RpcException(e.getMessage(),e);
}finally{
providers.add(invoker.getUrl().getAddress());
}
}
throw new RpcException("抛出异常...");
}
- 如上代码(2)从url参数里面获取设置的重试次数,如果用户没有设置则取默认的值,默认是重试2,这里需要注意的是代码(2)是获取配置重试次数又+1了。这说明 总共调用次数=重试次数+1 (1是正常调用)。
- 代码(3)循环重复试用,如果第一次调用成功则直接跳出循环返回,否则循环重试。第一次调用时不会走代码(3.1)(3.2)(3.3)。如果第一次调用出现异常,则会循环,这时候i=1,所以会执行代码(3.1)检查是否有线程调用了当前ReferenceConfig的destroy()方法,销毁了当前消费者。如果当前消费者实例已经被消费,那么重试就没有意义了,所以会抛出RpcException异常。
- 如果当前消费者实例没被销毁,则执行代码(3.2)重新获取当前服务提供者列表,这是因为从第一次调开始到线程可能提供者列表已经变化了,获取列表后,然后执行(3.2)又一次进行了校验。校验通过则执行(3.4),根据负载均衡策略选择一个服务提供者,再次尝试调用。负载均衡策略的选择下节会讲解。
Dubbo的负载均衡策略
当服务提供方是集群的时候,为了避免大量请求一直落到一个或几个服务提供方机器上,从而使这些机器负载很高,甚至打死,需要做一定的负载均衡策略。Dubbo提供了多种均衡策略,缺省为random,也就是每次随机调用一台服务提供者的机器。
Dubbo提供的负载均衡策略
- Random LoadBalance:随机策略。按照概率设置权重,比较均匀,并且可以动态调节提供者的权重。
- RoundRobin LoadBalance:轮询策略。轮询,按公约后的权重设置轮询比率。会存在执行比较慢的服务提供者堆积请求的情况,比如一个机器执行的非常慢,但是机器没有挂调用(如果挂了,那么当前机器会从Zookeeper的服务列表删除),当很多新的请求到达该机器后,由于之前的请求还没有处理完毕,会导致新的请求被堆积,久而久之,所有消费者调用这台机器上的请求都被阻塞。
- LeastActive LoadBalance:最少活跃调用数。如果每个提供者的活跃数相同,则随机选择一个。在每个服务提供者里面维护者一个活跃数计数器,用来记录当前同时处理请求的个数,也就是并发处理任务的个数。所以如果这个值越小说明当前服务提供者处理的速度很快或者当前机器的负载比较低,所以路由选择时候就选择该活跃度最小的机器。如果一个服务提供者处理速度很慢,由于堆积,那么同时处理的请求就比较多,也就是活跃调用数目越大,这也使得慢的提供者收到更少请求,因为越慢的提供者的活跃度越来越大。
- ConsistentHash LoadBalance:一致性Hash策略。一致性Hash,可以保证相同参数的请求总是发到同一提供者,当某一台提供者挂了时,原本发往该提供者的请求,基于虚拟节点,平摊到其他提供者,不会引起剧烈变动。
一致性Hash负载均衡策略原理
在解决分布式系统中,负载均衡的问题可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用。
但是普通的余数Hash(Hash(比如用户id)%服务器机器数)算法伸缩性很差,当新增或者下线服务器机器时候,用户id与服务器的映射关系会大量失效。一致性Hash则利用Hash环对其进行了改进。
一致性Hash概述
为了能直观的理解一致性Hash的原理,这里结合一个简单的例子来讲解,假设有4台服务器,地址为ip1/ip2/ip3/ip4 。
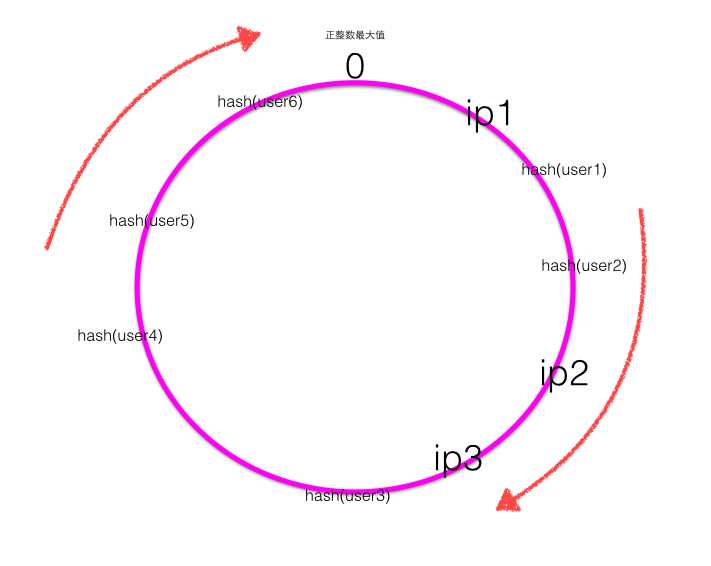
- 一致性Hash,首先计算四个ip地址对应的Hash值:hash(ip1) / hash(ip2) / hash(ip3) / hash(ip4) ,计算出来的Hash值是0~最大正整数之间的一个值,这四个值在一致性Hash环上呈现如下图:
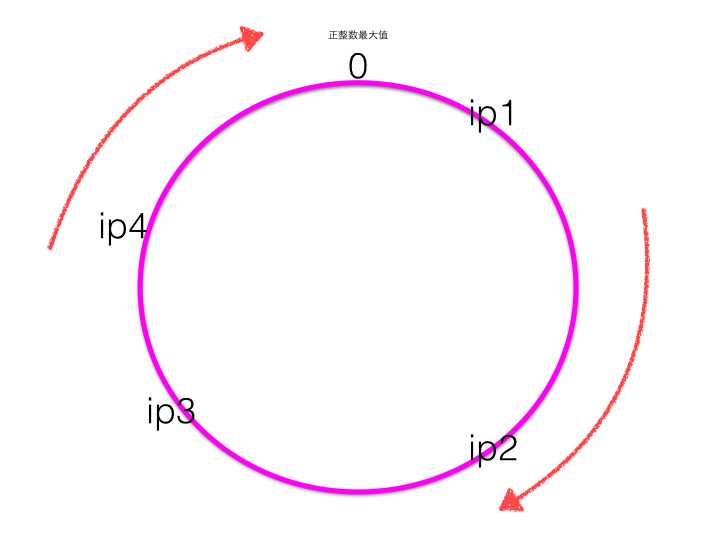
- Hash环上顺时针从整数0开始,一直到最大正整数,我们根据四个ip计算的Hash值肯定会落到这个Hash环上的某一个点,至此我们把服务器的四个ip映射到了一致性Hash环。
- 当用户在客户端进行请求时候,首先根据Hash(用户id)计算路由规则(Hash值),然后看Hash值落到了Hash环的哪个地方,根据Hash值在Hash环上的位置顺时针找距离最近的ip作为路由ip。
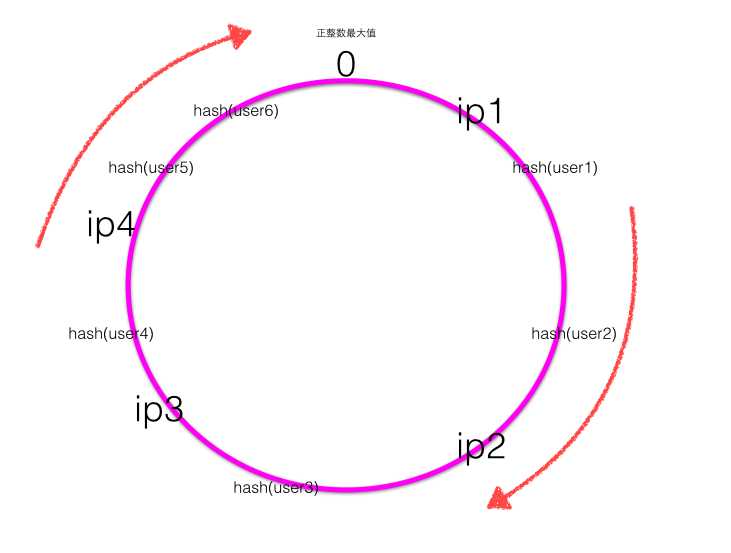
如上图可知user1 / user2的请求会落到服务器 ip2 进行处理,user3的请求会落到服务器ip3进行处理,user4的请求会落到服务器ip4进行处理,user5 / user6 的请求会落到服务器ip1进行处理。
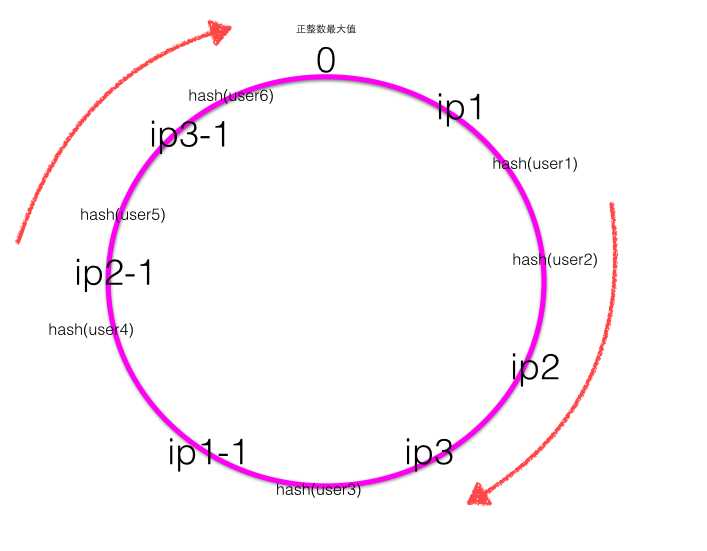
下面考虑当ip2的服务器挂了的时候会出现什么情况?
当ip2的服务器挂了的时候,一致性Hash环大致如下图:
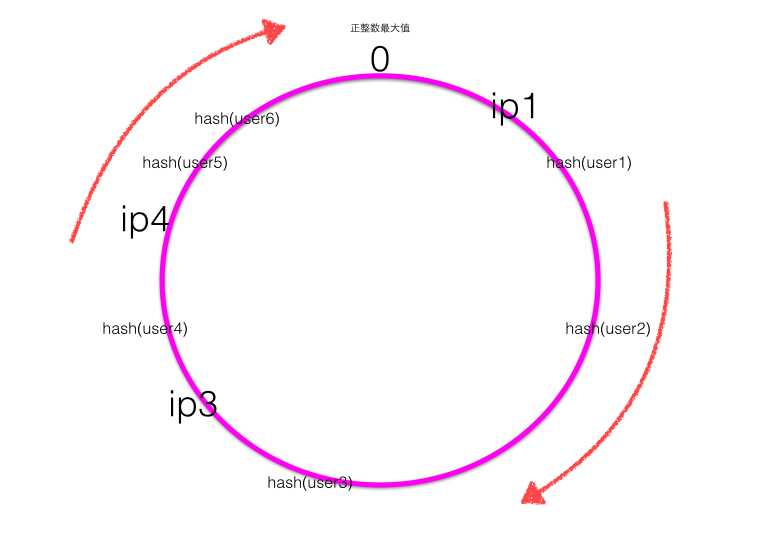
根据顺时针规则可知user1 / user2的请求会被服务器ip3进行处理,而其他用户的请求对应的处理服务器不变,也就是只有之前被ip2处理的一部分用户的映射关系被破坏了,并且其负责处理的请求被顺时针下一个节点委托处理。
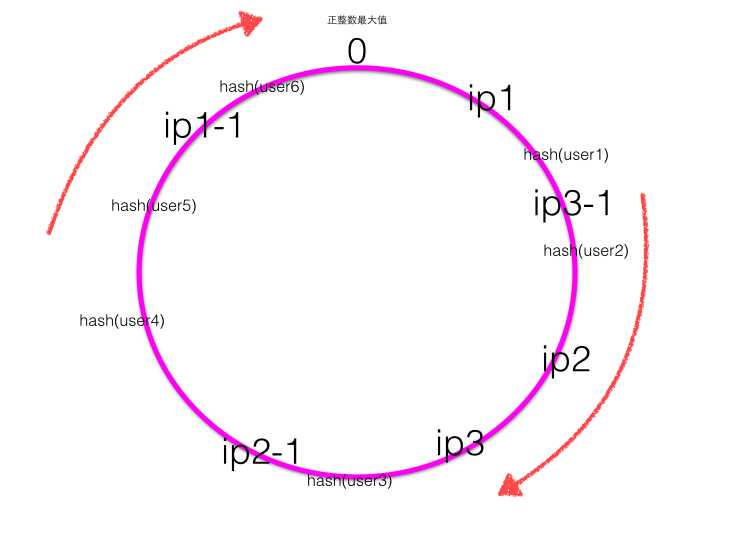
下面考虑当有新增机器加入时会出现什么情况?
当新增一个ip5的服务器后,一致性Hash环大致如下图:
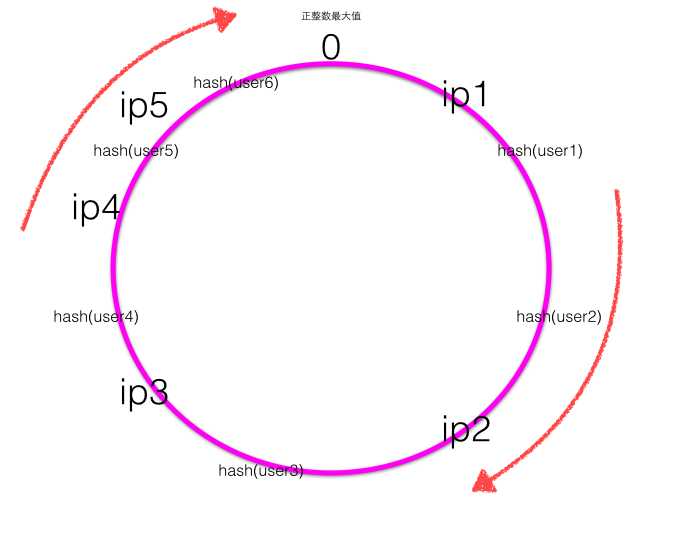
根据顺时针规则可知之前user1的请求应该被ip1服务器处理,现在被新增的ip5服务器处理,其他用户的请求处理服务器不变,也就是新增的服务器顺时针最近的服务器的一部分请求会被新增的服务器所替代。
一致性Hash的特性
一致性Hash有要有以下特性:
- 单调性(Monotonicity),单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时,应保证原有的请求可以被映射到原有的或者新的服务器中去,而不会被映射到原来的其他服务器上去。这一点通过上面新增服务器ip5可以证明,新增ip5后,原来被ip1处理的user6现在还是被ip1处理的user5现在被新增的ip5处理。
- 分散性(Spread):分布式环境中,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来它看到的部分服务器会形成一个完整的Hash环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理。这种情况显然是应该避免的,因为它不能保证同一个用户的请求落到同一个服务器。所谓分散性是指上述情况发生的严重程度。
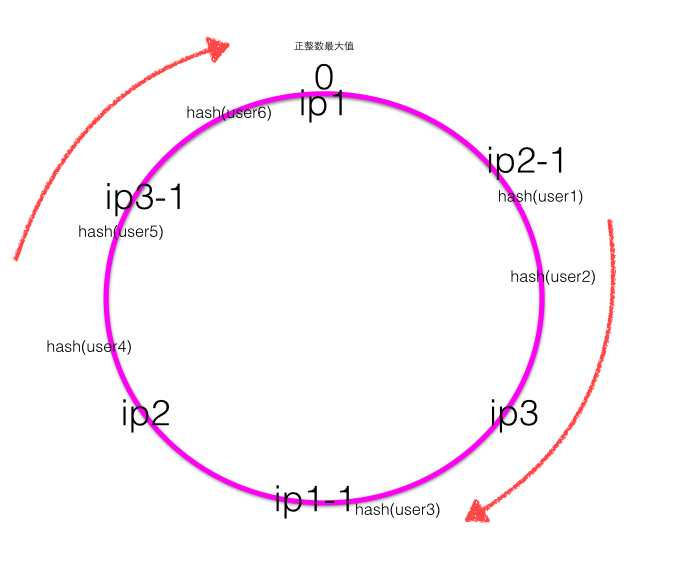
- 平衡性(Balance),平衡性也就是说负载均衡,是指客户端Hash后的请求应该能够分散到不同的服务器上去。一致性Hash可以做到每个服务器都进行处理请求,但是不能保证每个服务器处理的请求的数量大致相同,如下图:
服务器ip1 / ip2 / ip3经过Hash后落到了一致性Hash环上,从图中Hash值分布可知ip1会负责处理大概80%的请求,而ip2和ip3则只会负责处理大概20%的请求,虽然三个机器都在处理请求,但是明显每个机器的负载不均衡,这样称为一致性Hash的倾斜,虚拟节点的出现就是为了解决这个问题。
虚拟节点
当服务器节点比较少的时候会出现上节所说的一致性Hash倾斜的问题,一个解决方法是多加机器,但是加机器是有成本的,那么就加虚拟节点,比如上面三个机器,每个机器引入1个虚拟节点后的一致性Hash环如下图所示:
其中ip1-1是ip1的虚拟节点,ip2-1是ip2的虚拟节点,ip3-1是ip3的虚拟节点。
可知当物理机器数目为M,虚拟节点为N的时候,实际hash环上节点个数为 M*(N+1) 。比如当客户端计算的Hash值处于ip2和ip3或者处于ip2-1和ip3-1之间时候使用ip3服务器进行处理。
均匀一致性Hash
上节我们使用虚拟节点后的图看起来比较均衡,但是如果生成虚拟节点的算法不够好很可能会得到下面的环:
可知每个服务节点引入1个虚拟节点后,情况相比没有引入前均衡性有所改善,但是并不均衡。
均衡的一致性Hash应该如下图所示:
均匀一致性Hash的目标是如果服务器有N台,客户端的Hash值有M个,那么每个服务器应该处理大概 M/N 个用户的请求。也就是每台服务器均衡尽量均衡。Dubbo提供的一致性Hash就是不均匀的,这个大家可以去研究下ConsistentHashLoadBalance类。
原文:https://www.cnblogs.com/cnndevelop/p/12186960.html