ERNIE 2.0 详解
更新中
更新时间:2019-12-06 17:43:27
实验需要,在自己学习的过程中做如下笔记,欢迎指正,欢迎交流。
先看一下ERNIE 2.0的架构图:
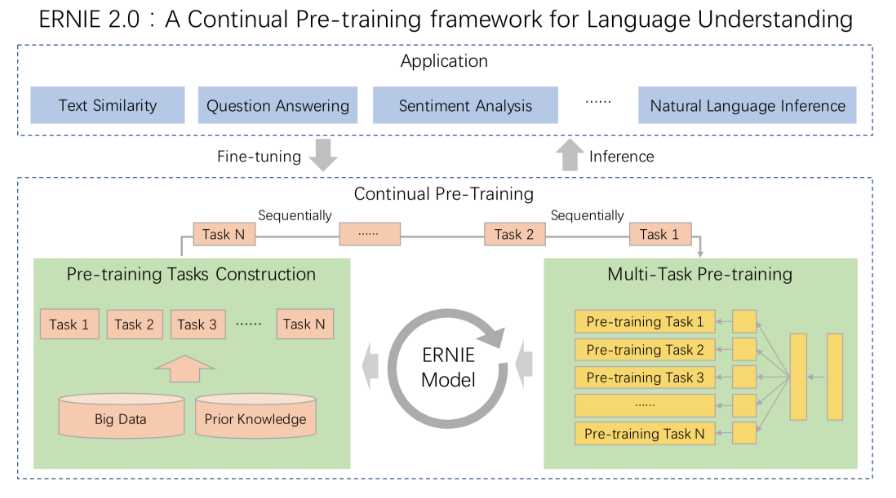
Application中,可以看到ernie支持各类NLP任务,在model的部分,基于百度的大数据及先验知识构建任务,进行基于多任务的预训练。
Pre-Training 任务
针对 ERNIE 2.0 模型,我们构建了多个预训练任务,试图从 3 个层面去更好的理解训练语料中蕴含的信息:
- Word-aware Tasks: 词汇 (lexical) 级别信息的学习
- Structure-aware Tasks: 语法 (syntactic) 级别信息的学习
- Semantic-aware Tasks: 语义 (semantic) 级别信息的学习
同时,针对不同的 pre-training 任务,ERNIE 2.0 引入了 Task Embedding 来精细化地建模不同类型的任务。不同的任务用从 0 到 N 的 ID 表示,每个 ID 代表了不同的预训练任务。

Word-aware Tasks
Knowledge Masking Task
- ERNIE 1.0 中已经引入的 phrase & named entity 知识增强 masking 策略。相较于 sub-word masking, 该策略可以更好的捕捉输入样本局部和全局的语义信息。
Capitalization Prediction Task
- 针对英文首字母大写词汇(如 Apple)所包含的特殊语义信息,我们在英文 Pre-training 训练中构造了一个分类任务去学习该词汇是否为大写。
Token-Document Relation Prediction Task
- 针对一个 segment 中出现的词汇,去预测该词汇是否也在原文档的其他 segments 中出现。
Structure-aware Tasks
Sentence Reordering Task
- 针对一个 paragraph (包含 M 个 segments),我们随机打乱 segments 的顺序,通过一个分类任务去预测打乱的顺序类别。
Sentence Distance Task
- 通过一个 3 分类任务,去判断句对 (sentence pairs) 位置关系 (包含邻近句子、文档内非邻近句子、非同文档内句子 3 种类别),更好的建模语义相关性。
Semantic-aware Tasks
Discourse Relation Task
- 通过判断句对 (sentence pairs) 间的修辞关系 (semantic & rhetorical relation),更好的学习句间语义。
IR Relevance Task
- 学习 IR 相关性弱监督信息,更好的建模句对相关性。
ERNIE 1.0: Enhanced Representation through kNowledge IntEgration
ERNIE 1.0 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。
这里我们举个例子:
Learnt by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
Learnt by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
在 BERT 模型中,我们通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的任何知识。而 ERNIE 通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是 『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
训练数据方面,除百科类、资讯类中文语料外,ERNIE 还引入了论坛对话类数据,利用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,进一步提升模型的语义表示能力。
对比 ERNIE 1.0 和 ERNIE 2.0
Pre-Training Tasks
| 任务 | ERNIE 1.0 模型 | ERNIE 2.0 英文模型 | ERNIE 2.0 中文模型 |
|---|---|---|---|
| Word-aware | ? Knowledge Masking | ? Knowledge Masking ? Capitalization Prediction ? Token-Document Relation Prediction |
? Knowledge Masking |
| Structure-aware | ? Sentence Reordering | ? Sentence Reordering ? Sentence Distance |
|
| Semantic-aware | ? Next Sentence Prediction | ? Discourse Relation | ? Discourse Relation ? IR Relevance |
原文:https://www.cnblogs.com/shona/p/11996759.html