12-HDFS详解二
1.HDFS读流程 面试题
[hadoop@hadoop001 hadoop]$ bin/hdfs dfs -cat /examples/output1/part-r-00000
19/07/07 20:09:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
a 3
b 2
c 3
ruozedata 2
www.ruozedata.com 1
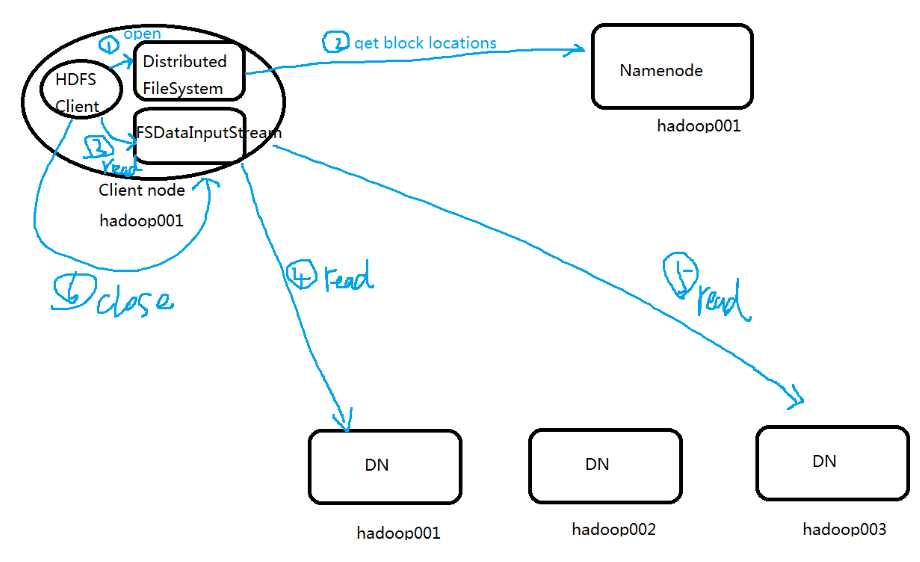
下图是读的过程
[hadoop@hadoop001 hadoop]$
上面的读对于我们用户是无感知的,不知道它从哪个节点上读
1.1 Client通过FileSystem.open(filePath)方法,与NN节点进行【rpc】协议通信,校验是否有权限是否存在,
假如都ok,返回该文件的部分或全部的block的列表(包含各个block块的分布在DN地址的列表),也就是返回【FSDataInputStream】对象;
1.2Clinet调用FSDataInputStream.read方法
a.与第一个块的最近的DN进行read,读取完成后,会check,假如ok,会关闭与当前的DN的通信;
假如失败会记录块的这个副本+DN信息,下次就不会从这读取。
那么就去该块的第二个DN的地址读取
b.然后读取第二个块,如第一个
c.假如block列表读取完成后,文件还未结束,那么FileSystem会从NN获取下一批次的block的列表。
当然读操作对于client,就是透明的,感觉就是连续的数据流
3.Client调用FSDataInputStream.close()方法,关闭输入流
下图是写的过程
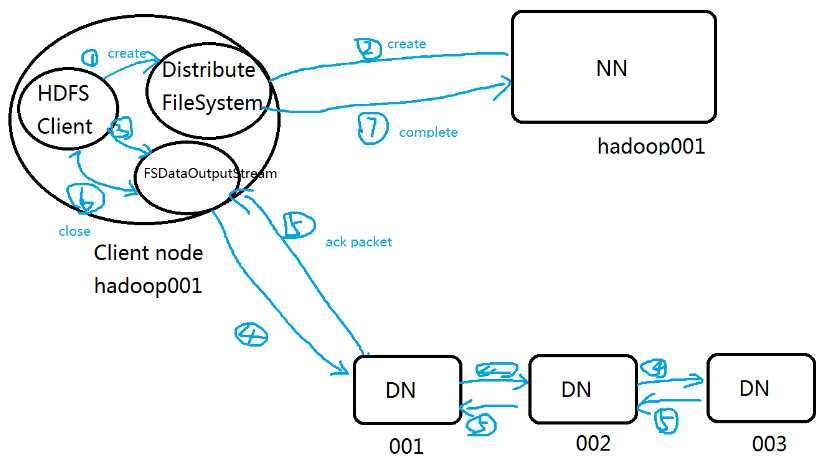
2.HDFS写流程 FSDataOutputStream
2.1 Client调用FileSystem.create(filePath)方法,
与NN进行【rpc】通信,检验该路径是否有权限创建是否文件存在,
假如ok,就创建一个新的文件,但不关联任何的block,
返回一个【FSDataOutputStream】
(假如不ok,直接返回错误,代码加try catch)
2.2 Client调用FSDataOutputStream.write方法
a.将第一个块的第一个副本写入DN1,
第一个副本写完传输给第二个DN2,
第二个副本写完就传输给第三个DN3,
当第DN3写完,就返回一个ack packet给DN2,
DN2就返回ack packet给DN1,
DN1就返回ack packet给FSDataOutputStream对象,
标识第一个块的三个副本都写完了
b.余下的块依次这样
2.3 当向文件写入数据完成后,Client调用FSDataOutputStream.close()方法,关闭输出流
2.4 再调用FileSystem.complete()方法,告诉NN节点写入成功。
原文:https://www.cnblogs.com/python8/p/11932830.html