docker随笔10--mysql集群准备
1.mysql中存在的问题(背景):
单一mysql,如果面临高并发,和海量存储时不满足需求
2.mysql的集群解决方案:
- 读写分离(主从)-->读多写少
主库:写入数据
从库:读库
要求: 两个库的数据完全一致
写库必须到主库
读库必须到从库
缺点:
应用程序需要连接多个节点,对应应用程序的开发变得复杂----->通过中间件来解决(不使用中间件的情况下,也可以在程序中手动分离,可利用aop编程,可以利用不同的控制器方法名称的前缀区分)
主从之间的同步是异步的,弱一致性,数据同步到主库以后,比如网络延时等情况可能同步到从库失败,这样主从库数据就会不一样了(数据丢失了),对于数据安全要求较高的项目不合理。------>可以通过pxc解决
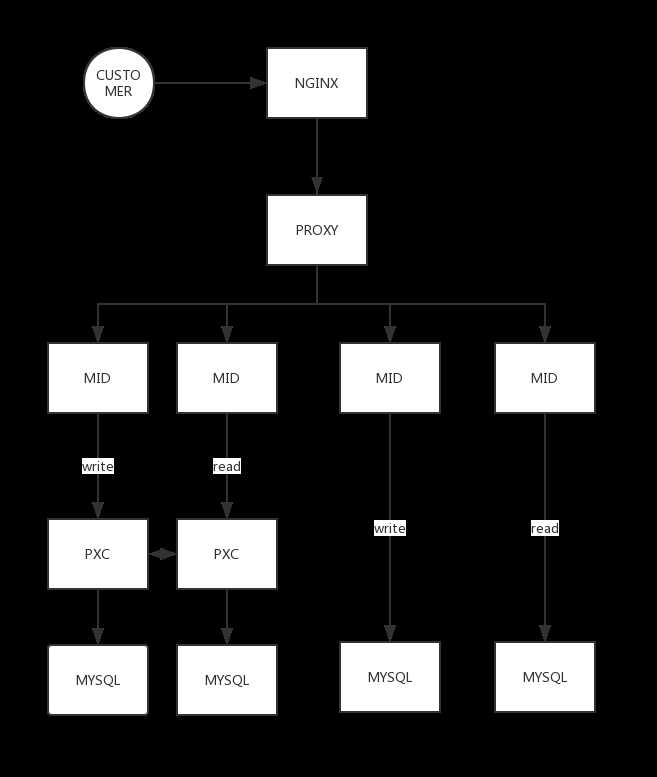
mysql中间件(mycat):
使用中间件进行读写分离以后,所有的请求的压力都会集中在中间件上,中间件的性能成了整个系统的性能瓶颈,所以可以布置多个中间件,再通过负载均衡调度请求每个中间件的数量 。
整理流程:应用请求(读写操作)---->负载均衡(代理)---->请求中间件(中间件节点)----->区分读写操作------>请求主库(从库)
可以对中间件也进行集群化部署。
- 混合架构:
因为使用pxc的,强一致性会损失很多的性能,所以通过中间件的根据特定的表走pxc,一般的则使用主从复制即可。
3.主从复制原理:
- master节点将增量的操作,记录到一个二进制日志中(binary log),mysql配置文件中log-bin中指定的文件。
- slave节点将master中的二进制日志拷贝到它的中继日志(relay log)
- slave将中继日志中的操作重新执行一次。
注意点:
master的mysql版本和slave的版本要一致。
master和slave中的数据需要一致
master开启二进制日志,master和slave中的server_id都要唯一。
mysql中的my.cnf配置文件中中log-bin可以制定binary log的名字。
4.原理图如下
原文:https://www.cnblogs.com/callmelx/p/11116232.html