hadoop搭建
一,安装配置jdk
1,上传jdk
2,建app文件夹 mkdir app ,将jdk解压到app中
将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
刷新权限:source /etc/profile
二,安装配置hadoop
1,上传hadoop
2, 将hadoop解压到app中
目录:
3,修改配置文件
hadoop-env.sh

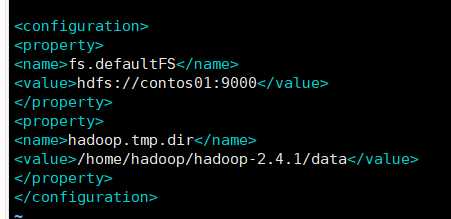
core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/data/</value>
</property>
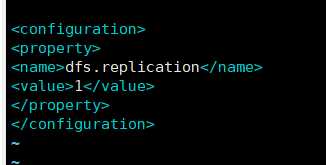
hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
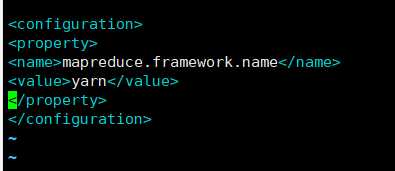
mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
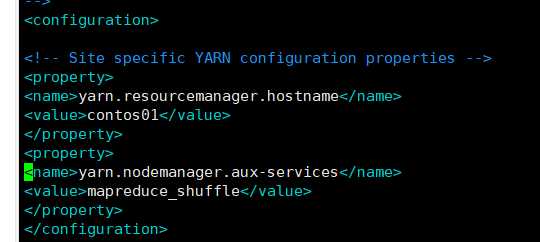
yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend-1206-01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4,将hadoop添加到环境变量
sudo vim /etc/proflie
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5,关闭防火墙
查看status:sudo service iptables status
停止:sudo service iptables stop
将自动启动关闭:看状态sudo chkconfig iptables --list

全部设为off
sudo chkconfig iptables off

6,格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
成功
![]()
启动hadoop
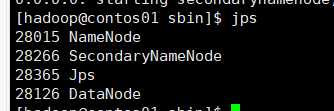
先启动HDFS
sbin/start-dfs.sh
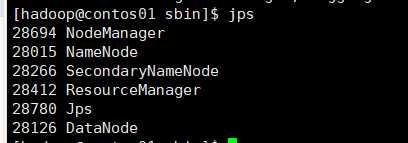
再启动YARN
sbin/start-yarn.sh
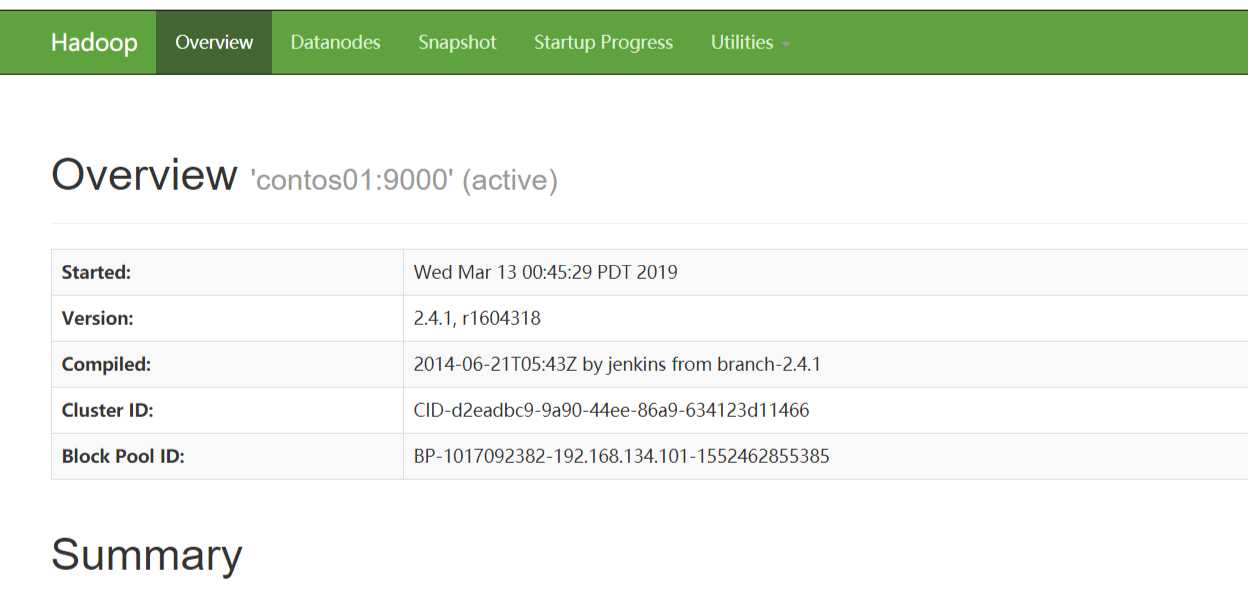
到此启动成功可以在页面访问
http://192.168.134.101:50070 (HDFS管理界面)
http://192.168.1.101:8088 (MR管理界面)
以下是访问到的页面
原文:https://www.cnblogs.com/dhqz/p/10523659.html